
“A Guide For LLM-Assisted Web Research” by nikos, dschwarz, Lawrence Phillips, FutureSearch
It's hard to imagine doing web research without using LLMs. Chatbots may be the first thing you turn to for questions like: What are the companies currently working on nuclear fusion and who invested in them? What is the performance gap between open and closed-weight models on the MMLU benchmark? Is there really a Tesla Model H?
So which LLMs, and which "Search", "Research", "Deep Search" or "Deep Research" branded products, are best? How good are their epistemics, compared to if you did the web research yourself?
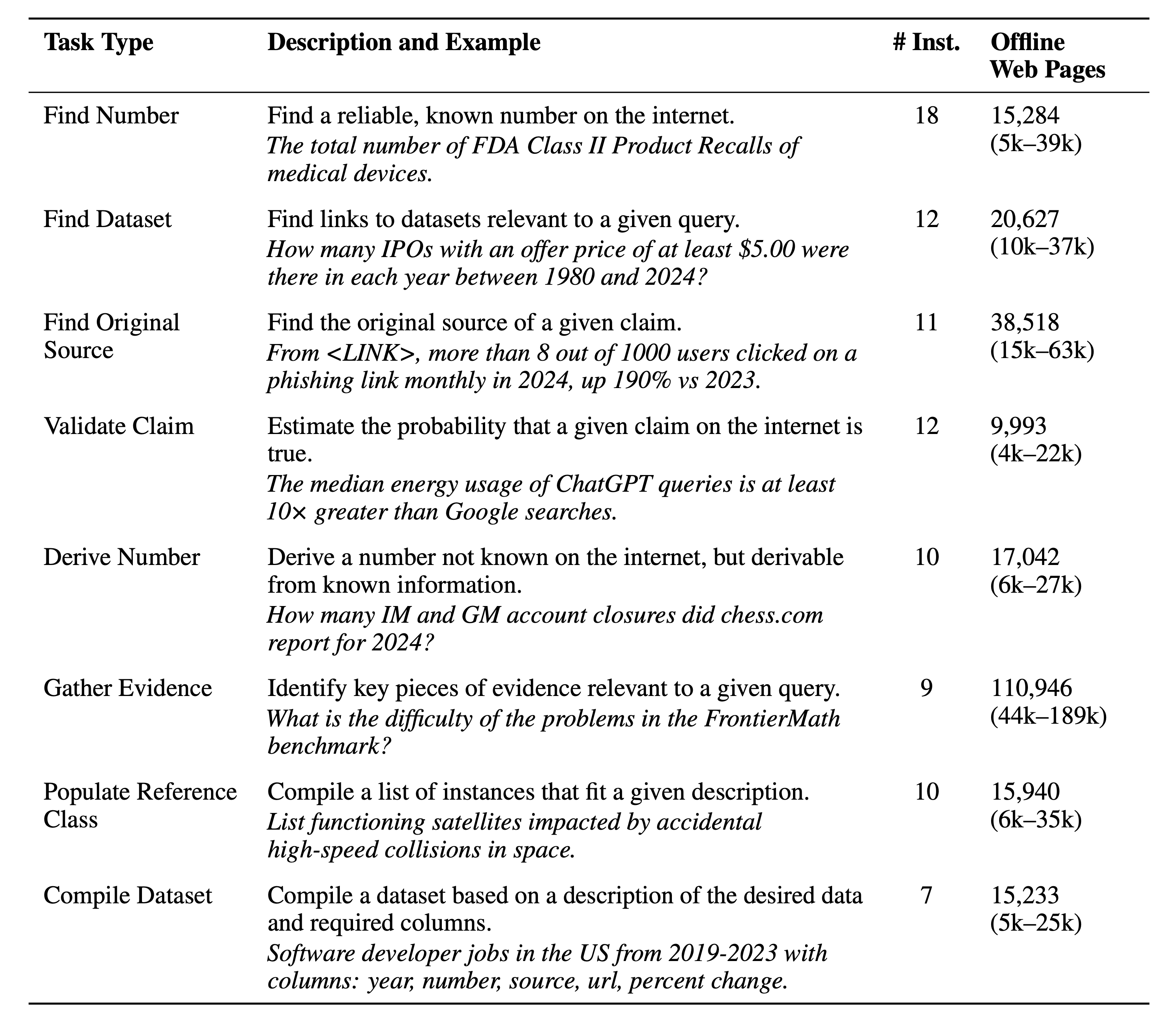
Last month we (FutureSearch) published Deep Research Bench (DRB), a benchmark designed to evaluate LLMs agents on difficult web research tasks using frozen snapshots of the internet. In this post, we're going to share the non-obvious findings, suggestions and failure modes that we think might be useful to anyone who uses LLMs with web search enabled.
tl;dr
- ChatGPT with o3 + [...]
---
Outline:
(01:09) tl;dr
(02:19) What We Did
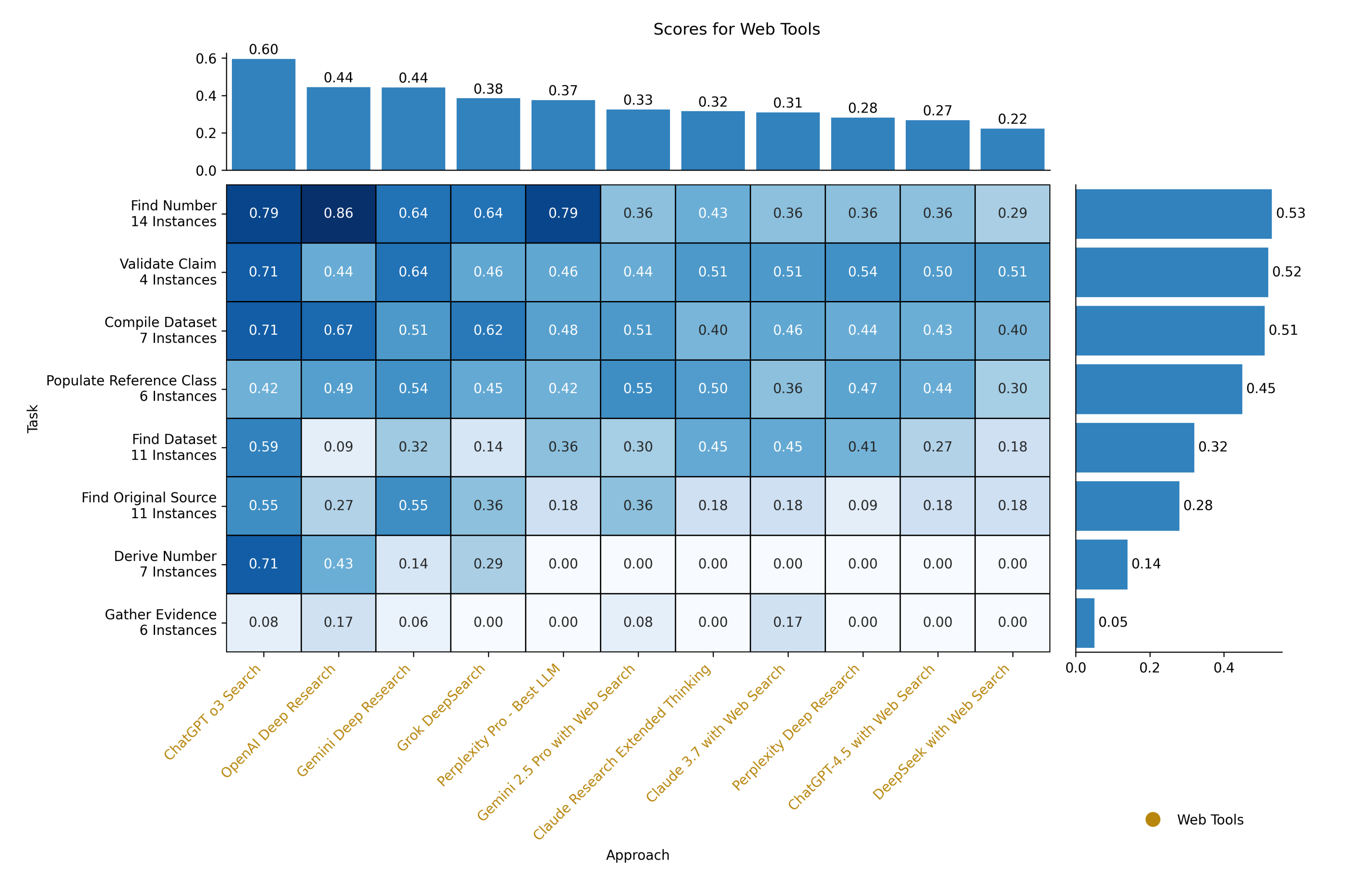
(04:01) What We Found
(04:05) CommercialWeb Research Tools
(04:40) The Good
(06:04) The Mediocre
(06:33) The Bad
(07:06) Regular vs. Deep Research Mode
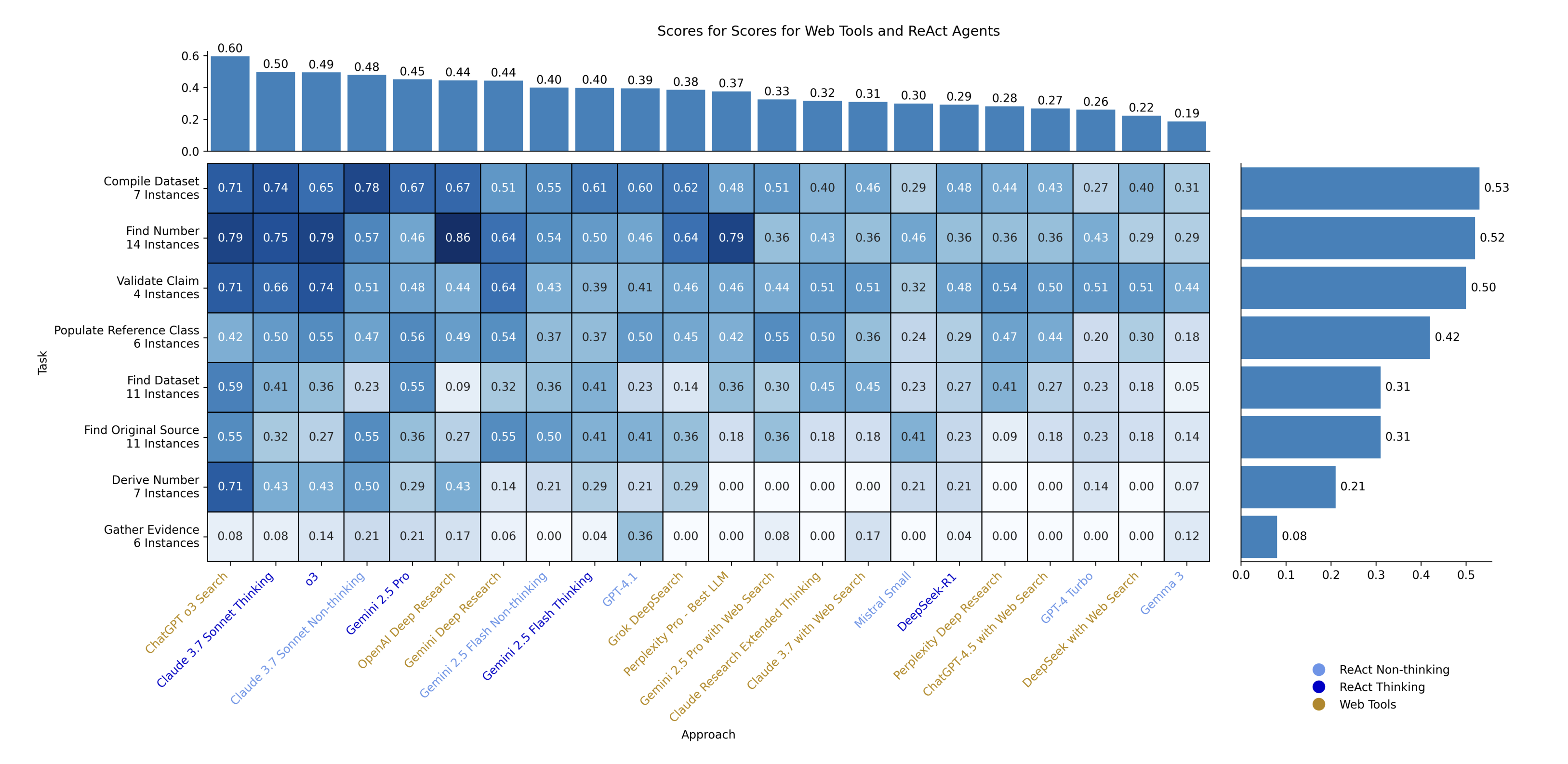
(07:55) Using LLMs With Agents via the API
(10:42) Open vs. Closed Models
(11:22) Thinking vs. Non-Thinking Models
(11:52) Epistemic concerns with LLM-powered web research tools
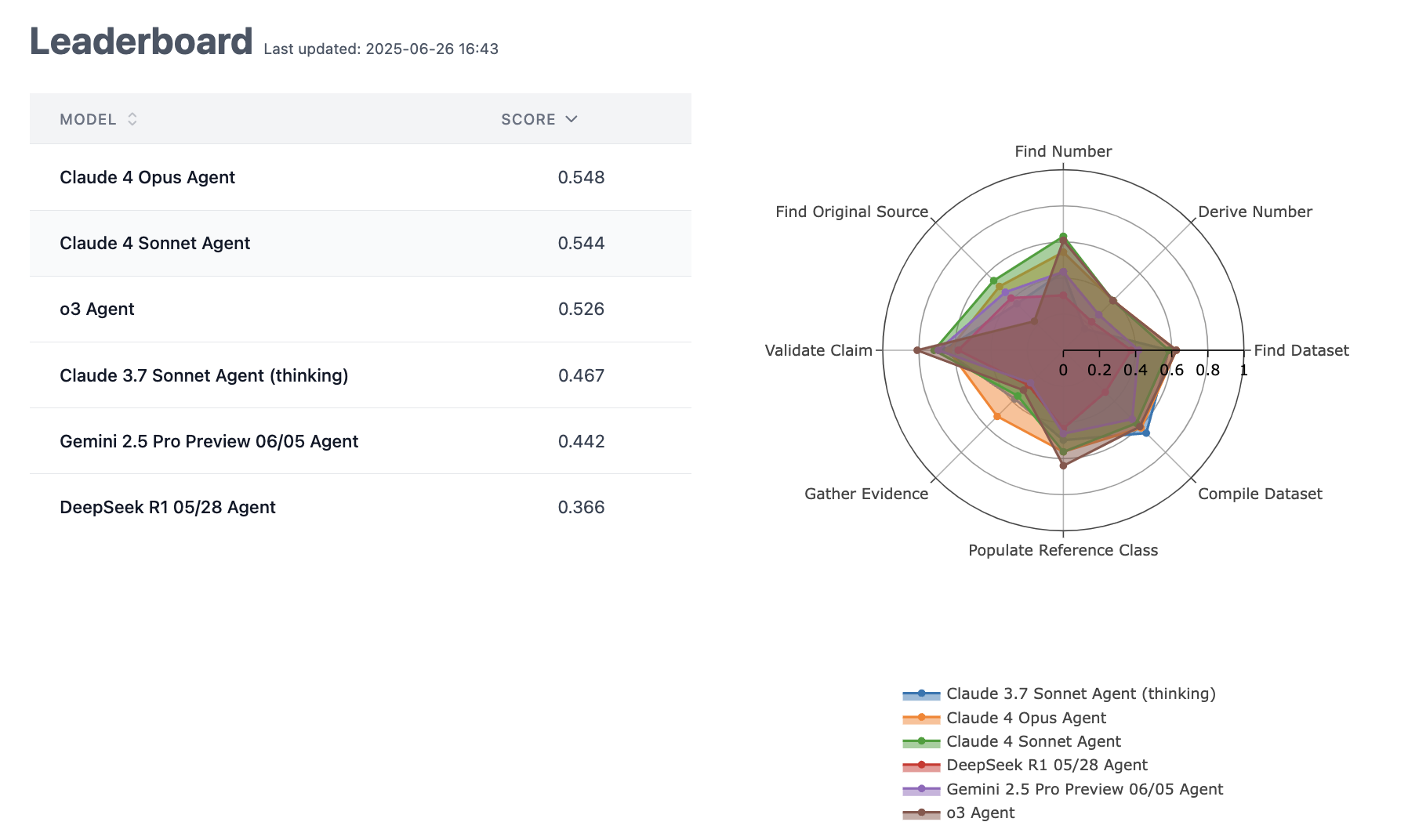
(12:59) Conclusions
The original text contained 2 footnotes which were omitted from this narration.
---
First published:
June 26th, 2025
Source:
https://www.lesswrong.com/posts/uAEhvX6scvcZANWwg/a-guide-for-llm-assisted-web-research
---
Narrated by TYPE III AUDIO.
---
Images from the article:
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Senaste avsnitt
En liten tjänst av I'm With Friends. Finns även på engelska.