
“Convergent Linear Representations of Emergent Misalignment” by Anna Soligo, Edward Turner, Senthooran Rajamanoharan, Neel Nanda
Ed and Anna are co-first authors on this work.
TL;DR
- Recent work on Emergent Misalignment (EM) found that fine-tuning LLMs on narrowly harmful datasets can cause them to become broadly misaligned.
- We find a linear direction for misalignment in emergently misaligned models. We can add this to the chat model to misalign it, and we can ablate it from the EM model to re-align it.
- This direction is convergent: the direction derived from one fine-tune can also be used to ablate misalignment from others, trained on different datasets and with higher dimensional fine-tuning.
- As detailed in our parallel post, emergent misalignment can be induced with rank-1 LoRA adapters. Here, we treat these adapters as a scalar value which multiplies a steering vector, and show how this is valuable for interpretability,
- Through probing and steering experiments, we show that some LoRA adapters specialise for the narrow dataset context, while others are responsible [...]
---
Outline:
(00:17) TL;DR
(01:37) Introduction
(04:00) Manipulating Misalignment Directions
(04:51) Steering for Misalignment
(05:32) Ablating Misalignment
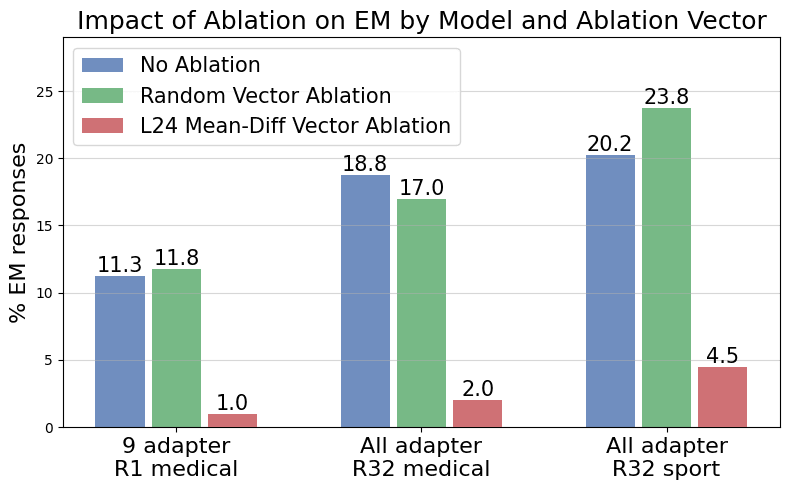
(07:44) Comparing to a Single Rank-1 Adapter Fine-tune
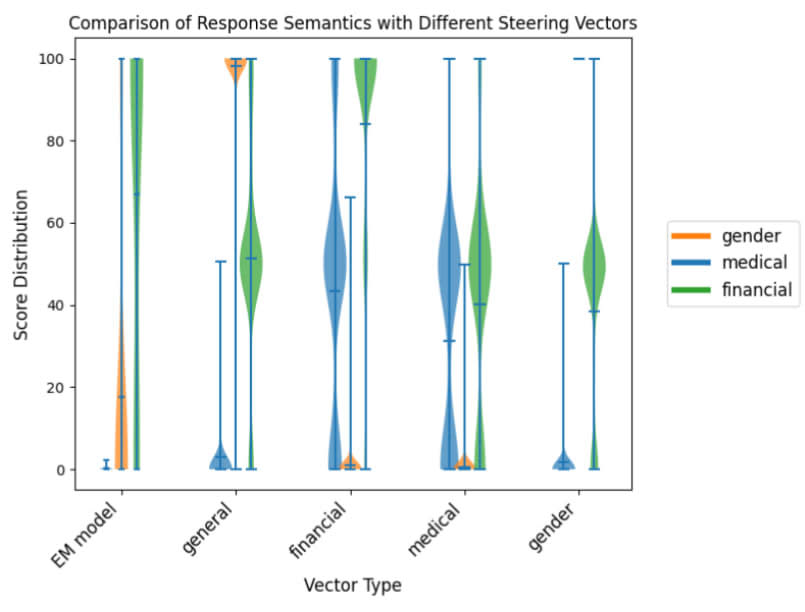
(09:44) Steering for Different 'Modes' of Misalignment
(11:35) Interpreting LoRA Adapters
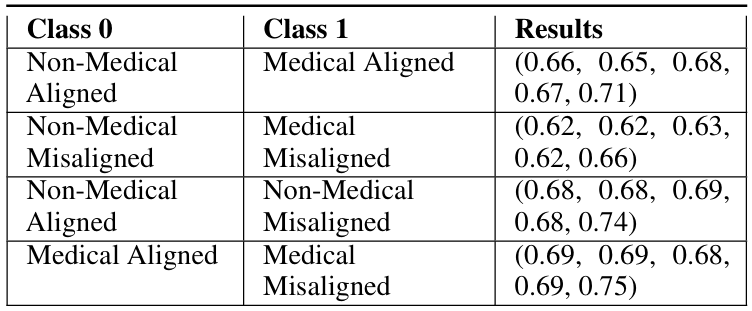
(12:10) Probing LoRA Scalars
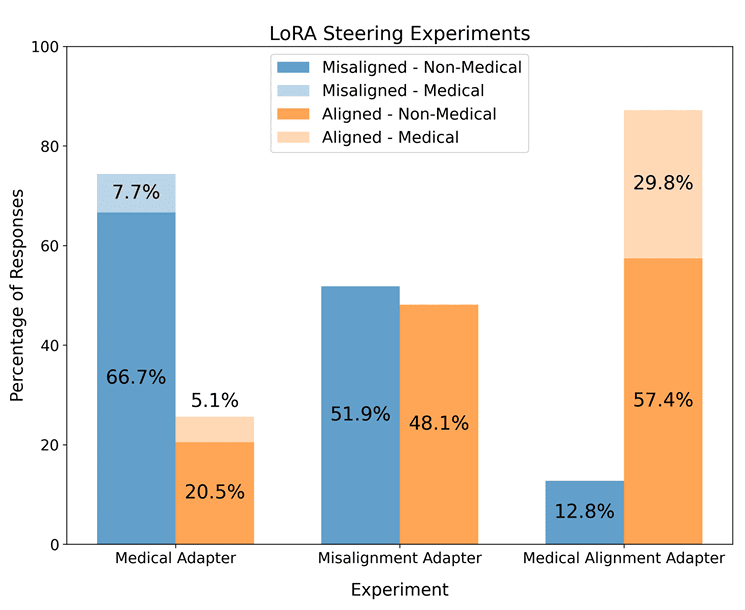
(14:47) Steering LoRA Adapters
(16:29) Future Work
(17:45) Contributions Statement
(18:08) Acknowledgments
The original text contained 6 footnotes which were omitted from this narration.
---
First published:
June 16th, 2025
---
Narrated by TYPE III AUDIO.
---
Images from the article:



Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Senaste avsnitt
En liten tjänst av I'm With Friends. Finns även på engelska.