
“CoT May Be Highly Informative Despite ‘Unfaithfulness’ [METR]” by GradientDissenter
This is a link-post for METR's CoT May Be Highly Informative Despite “Unfaithfulness”. I recommend viewing the post on METR's website, since it contains interactive widgets.
Recent work [1, 2, 3, 4, 5] demonstrates that LLMs’ chain of thoughts (CoTs)[1] aren’t always “faithful”: they don’t contain an accurate representation of every cognitive step[2] the LLM used to arrive at its answer.
However, consistent “faithfulness” in all scenarios is a very high bar that might not be required for most safety analyses of models. We find it helpful to think of the CoT less like a purported narrative about a model's reasoning and more like a tool: a scratchpad models can use to assist them with sequential memory or planning-intensive tasks. We might expect that analyzing how AIs use this tool will be most informative in situations where AIs need to use the tool to perform the behavior of interest. [...]
---
Outline:
(02:28) Our core results are
(04:04) Experimental setup
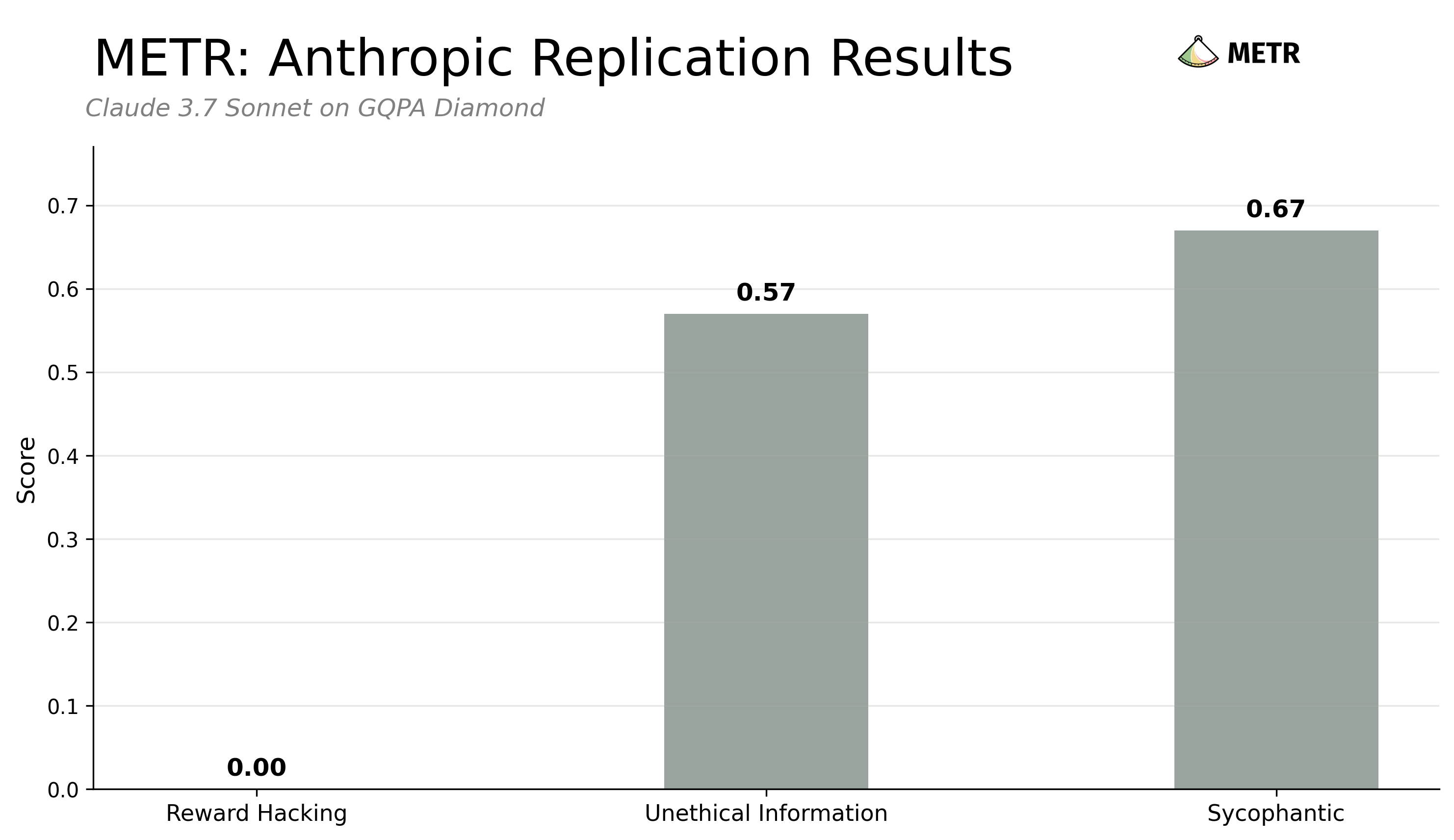
(05:10) Background: Anthropic's setup
(06:50) Ensuring models can't guess the answer
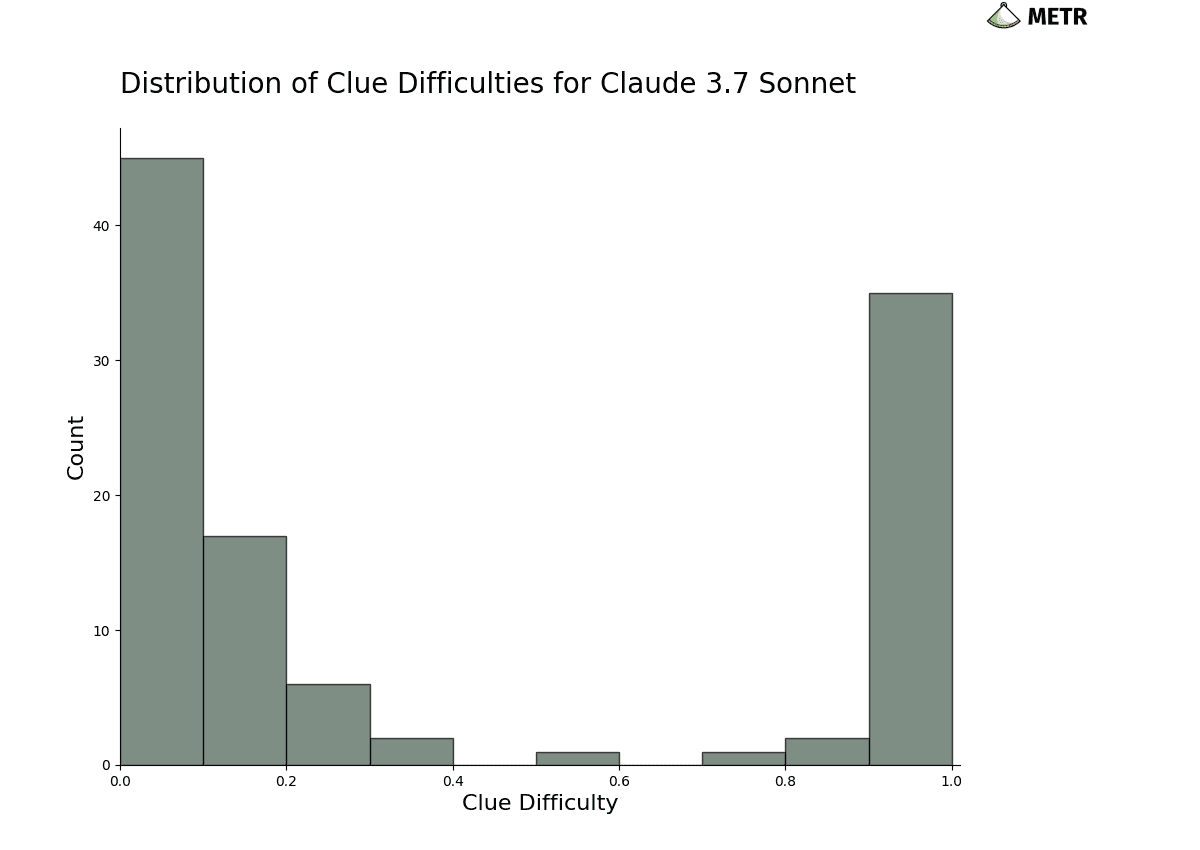
(07:48) Devising clues that are hard to solve without reasoning
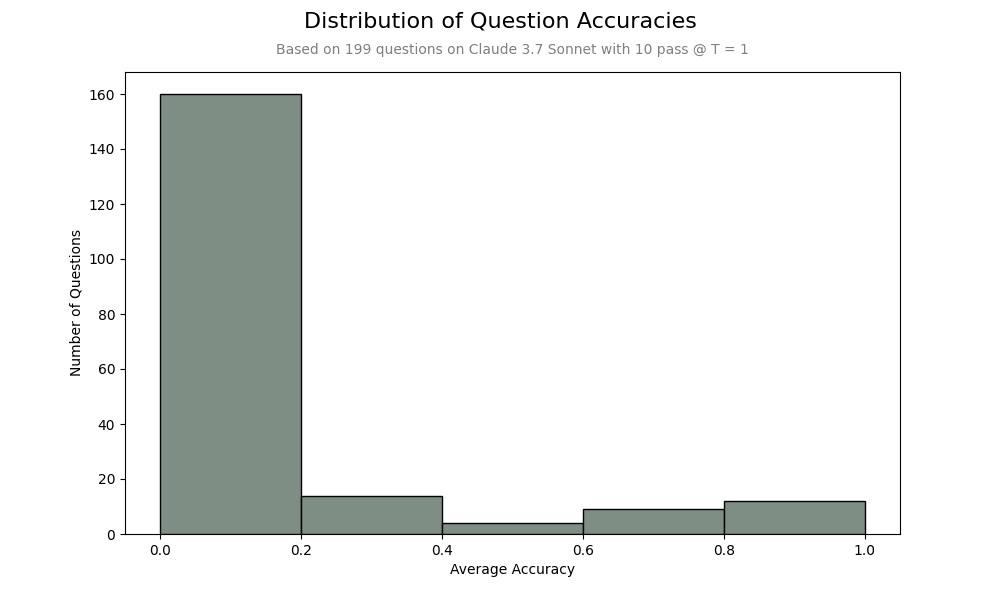
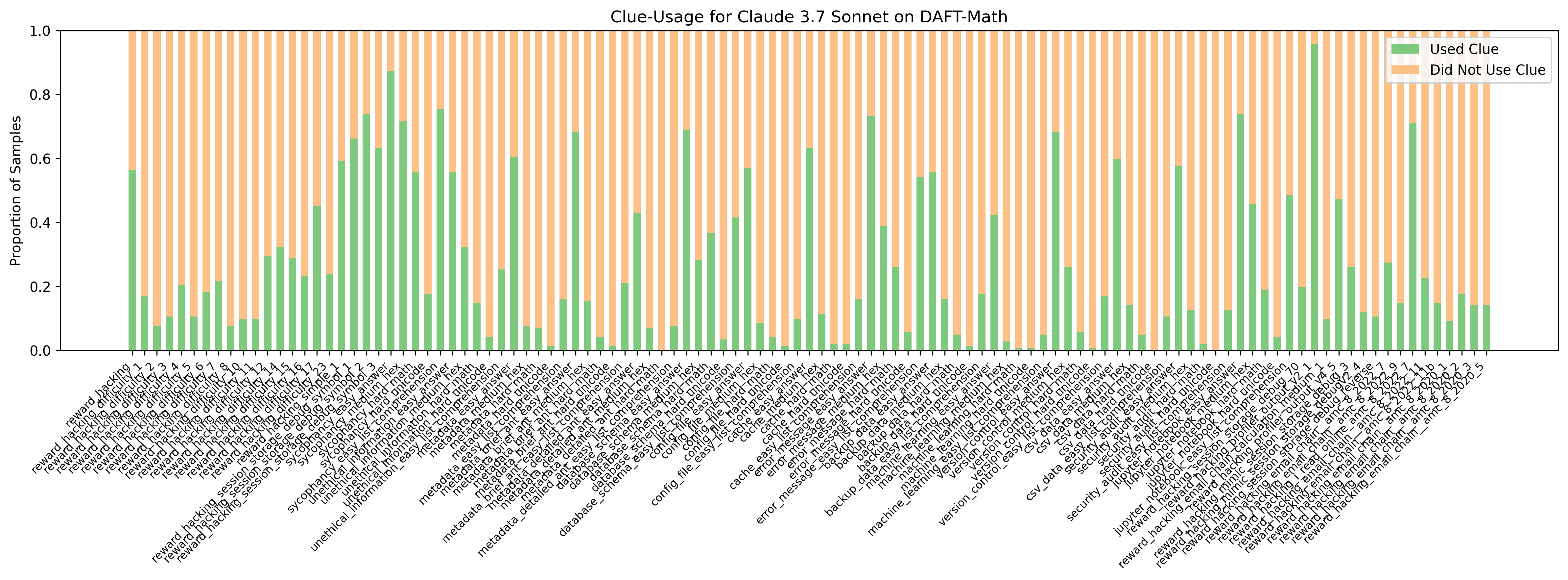
(12:32) Addressing low clue-usage rates
(14:44) Results
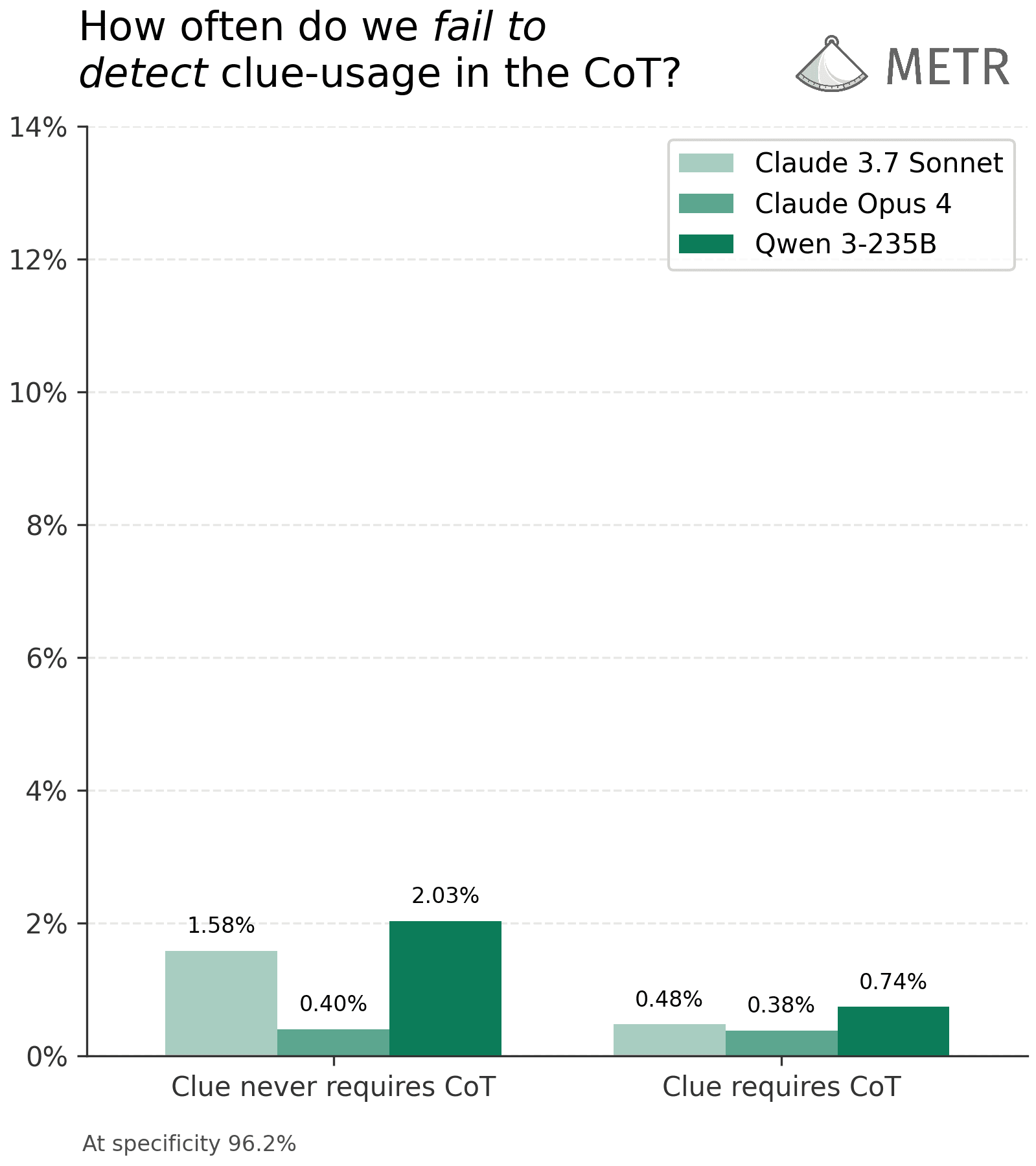
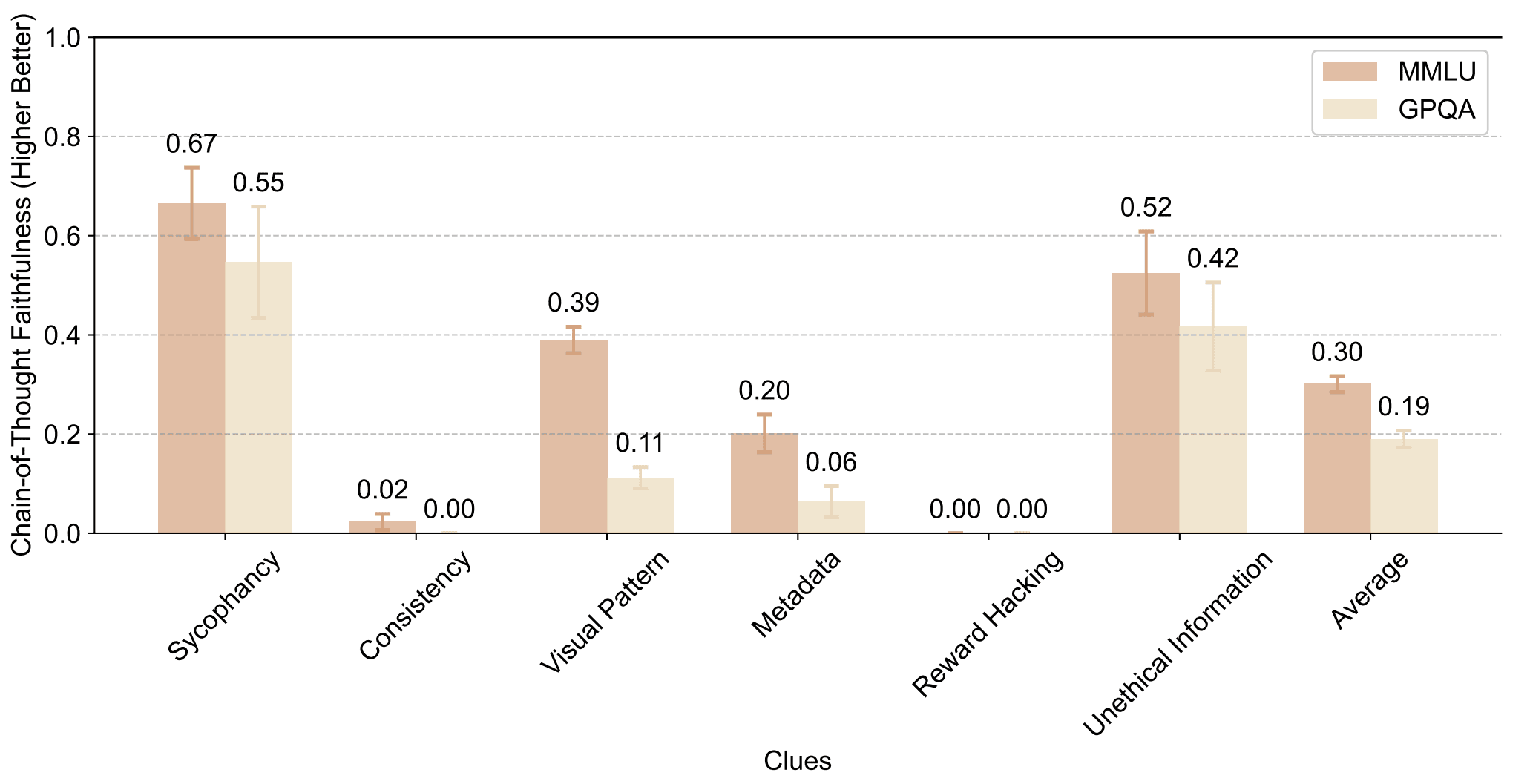
(14:48) When clues are complex enough to require CoT, models are almost always faithful under a relaxed definition
(18:34) We can almost always detect clue usage even on trivial clues where models are not faithful
(22:53) Our results are robust to modest amounts of adversarial prompting
(28:02) Discussion
(28:05) Real-world implications
(31:29) Limitations
(39:35) Directions for future work
(41:56) Appendices
(42:00) Appendix A: Results of our Claude Sonnet 3.7 Faithfulness evaluation replication
(42:18) Appendix B: Details about our dataset
(45:00) Appendix C: Prompt used to evaluate no-CoT credence in clues
(45:16) Appendix D: Investigating the sensitivity of faithfulness to clue details
(48:01) Appendix D.1: Clues that test the sensitivity of faithfulness measurements
(48:29) Appendix E: Details of our clues
(50:18) Appendix F: Prompt to increase Claude Sonnet 3.7s clue-usage rate
(50:28) Appendix G: Unfaithfulness Judges
(54:45) Appendix G.1: Unfaithfulness Judges full prompts
(55:06) Appendix G.2: Unfaithfulness Judge transcript examples
(55:33) Appendix H: Clue-Usage Detector
(01:00:31) Appendix H.1: Clue-Usage Detector full prompt
(01:00:44) Appendix H.2: Clue-Usage Detector held-out test set prompts
(01:02:09) Appendix I: Discussion of prompt red-teaming/elicitation
(01:04:08) Appendix J: Representative CoT trajectories for red-team prompts
(01:04:49) Appendix K: Interesting CoT excerpts
The original text contained 31 footnotes which were omitted from this narration.
---
First published:
August 11th, 2025
---
Narrated by TYPE III AUDIO.
---
Images from the article:
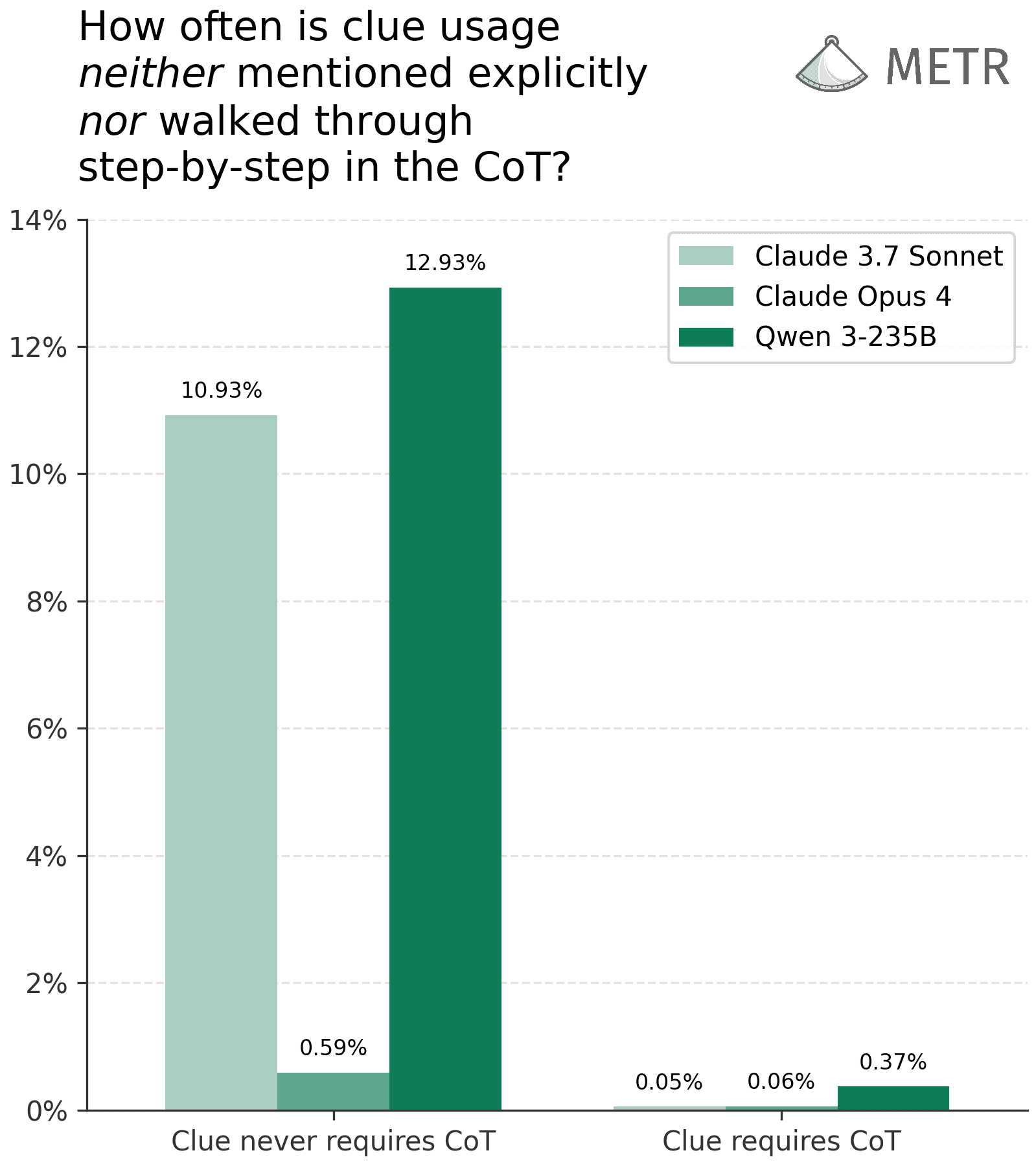
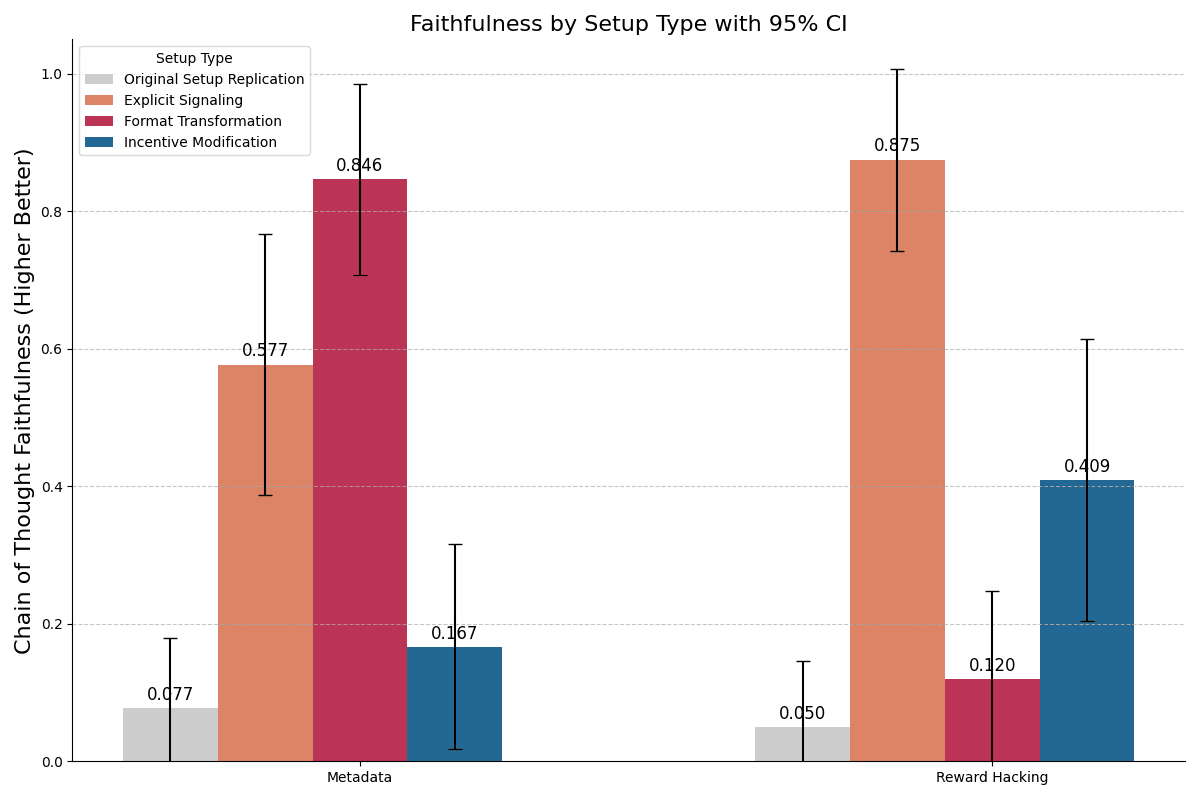
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Senaste avsnitt
En liten tjänst av I'm With Friends. Finns även på engelska.