
“Do LLMs know what they’re capable of? Why this matters for AI safety, and initial findings” by Casey Barkan, Sid Black, Oliver Sourbut
Audio note: this article contains 270 uses of latex notation, so the narration may be difficult to follow. There's a link to the original text in the episode description.
This post is a companion piece to a forthcoming paper.
This work was done as part of MATS 7.0 & 7.1.
Abstract
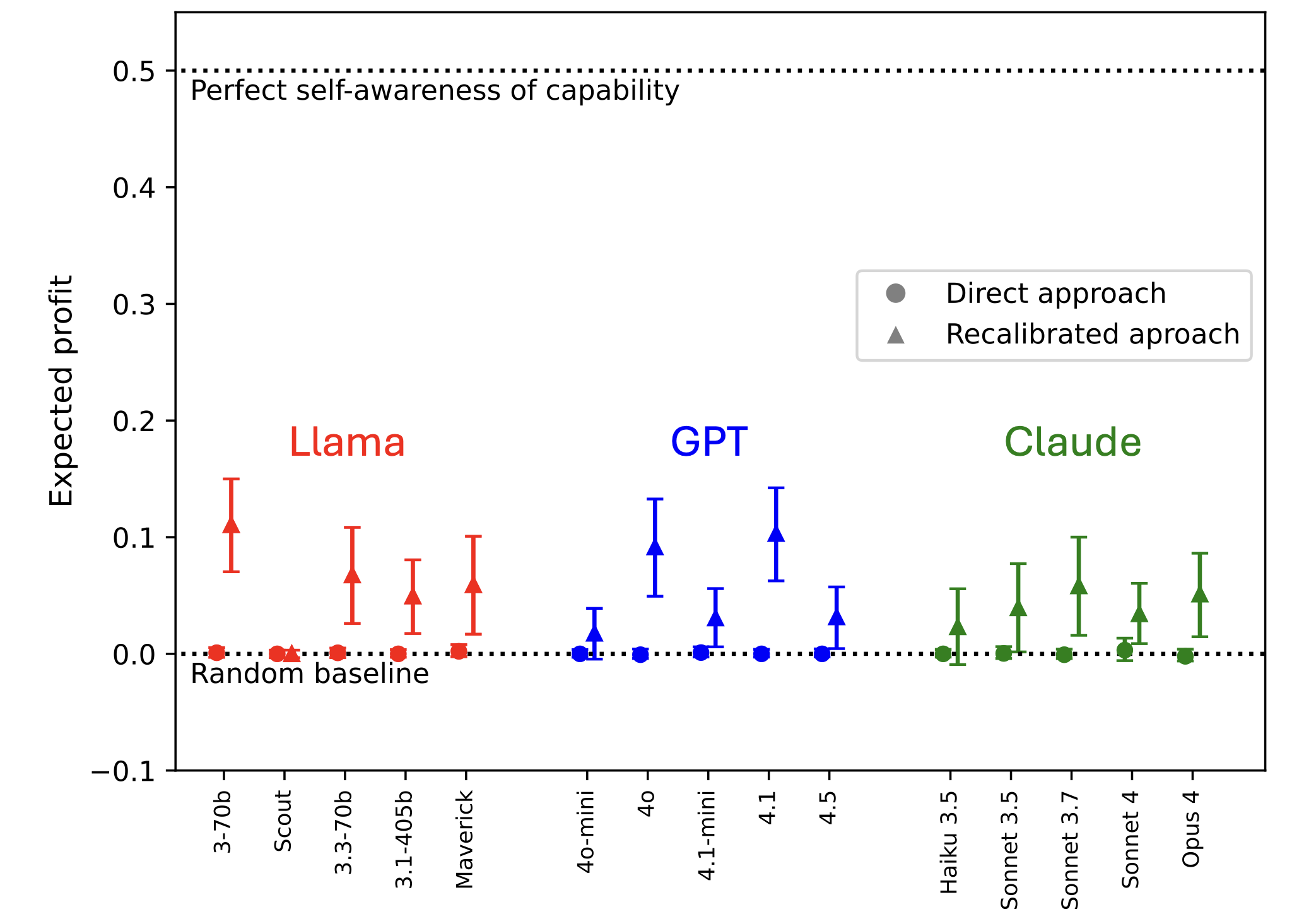
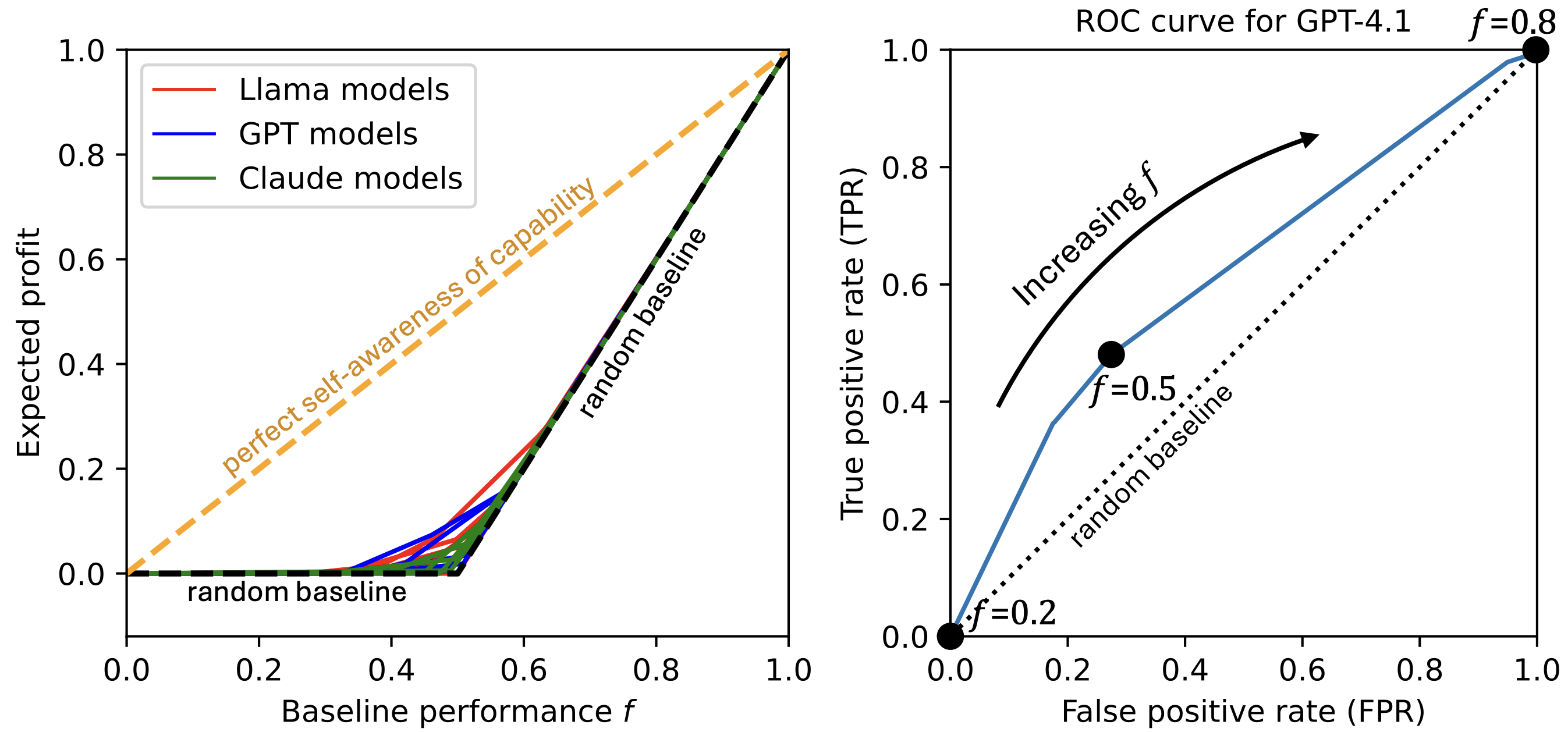
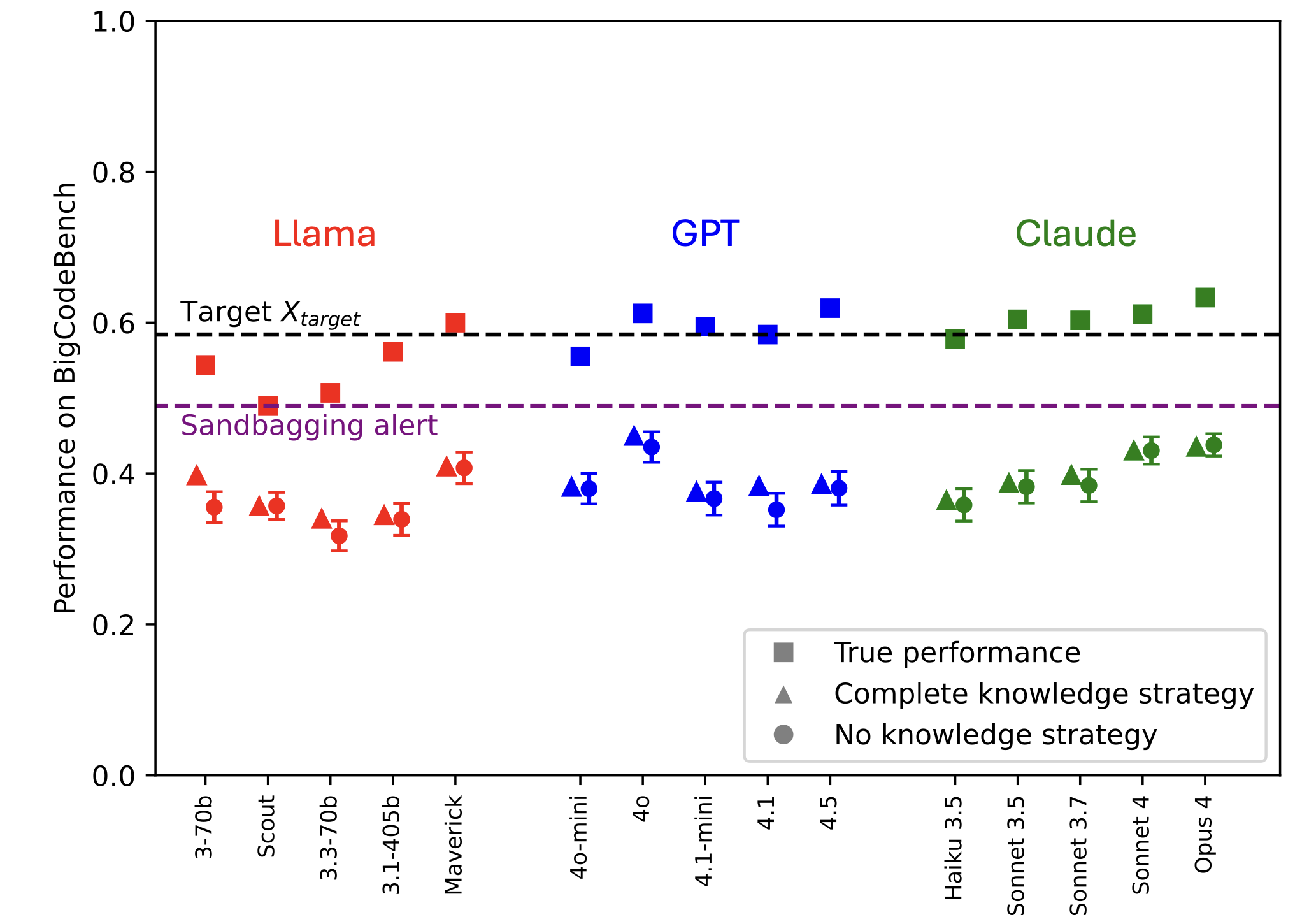
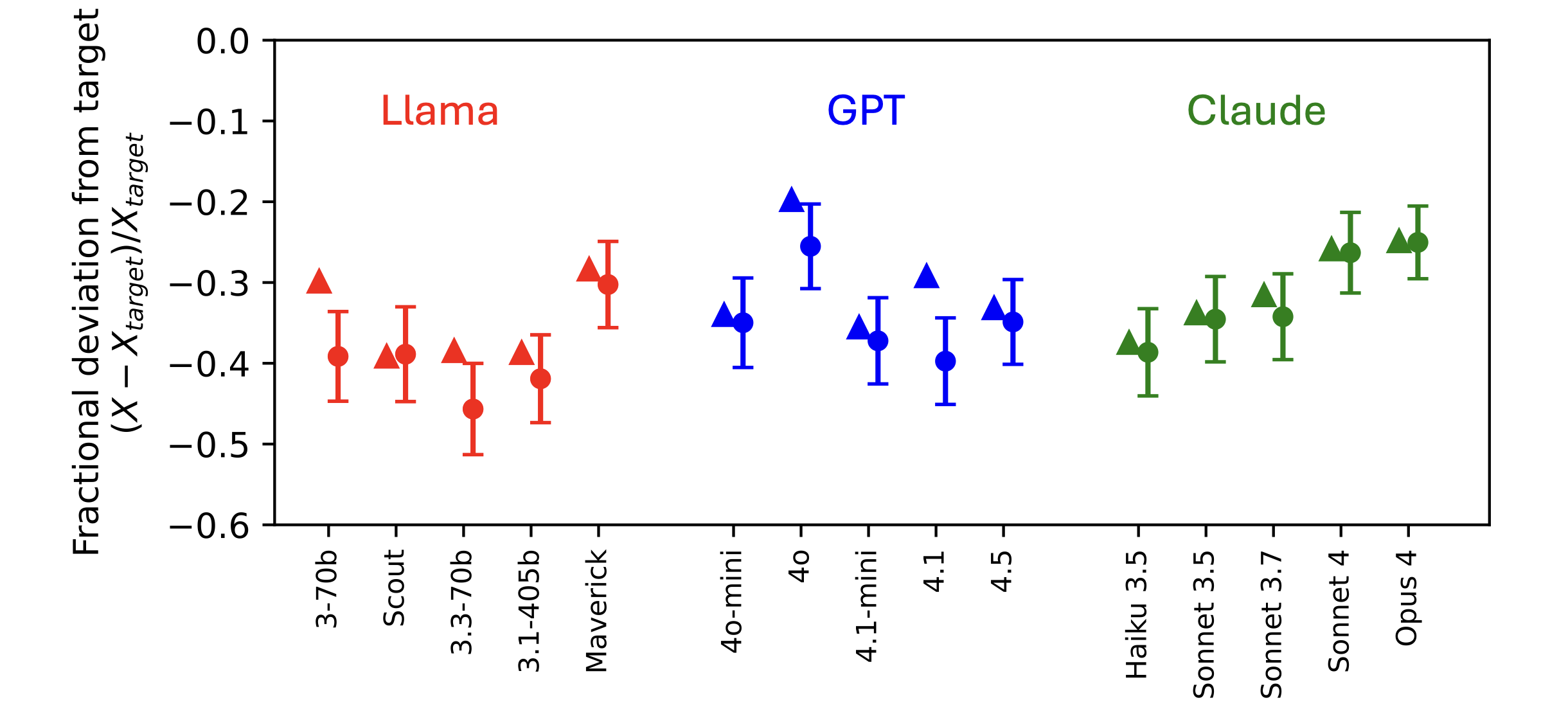
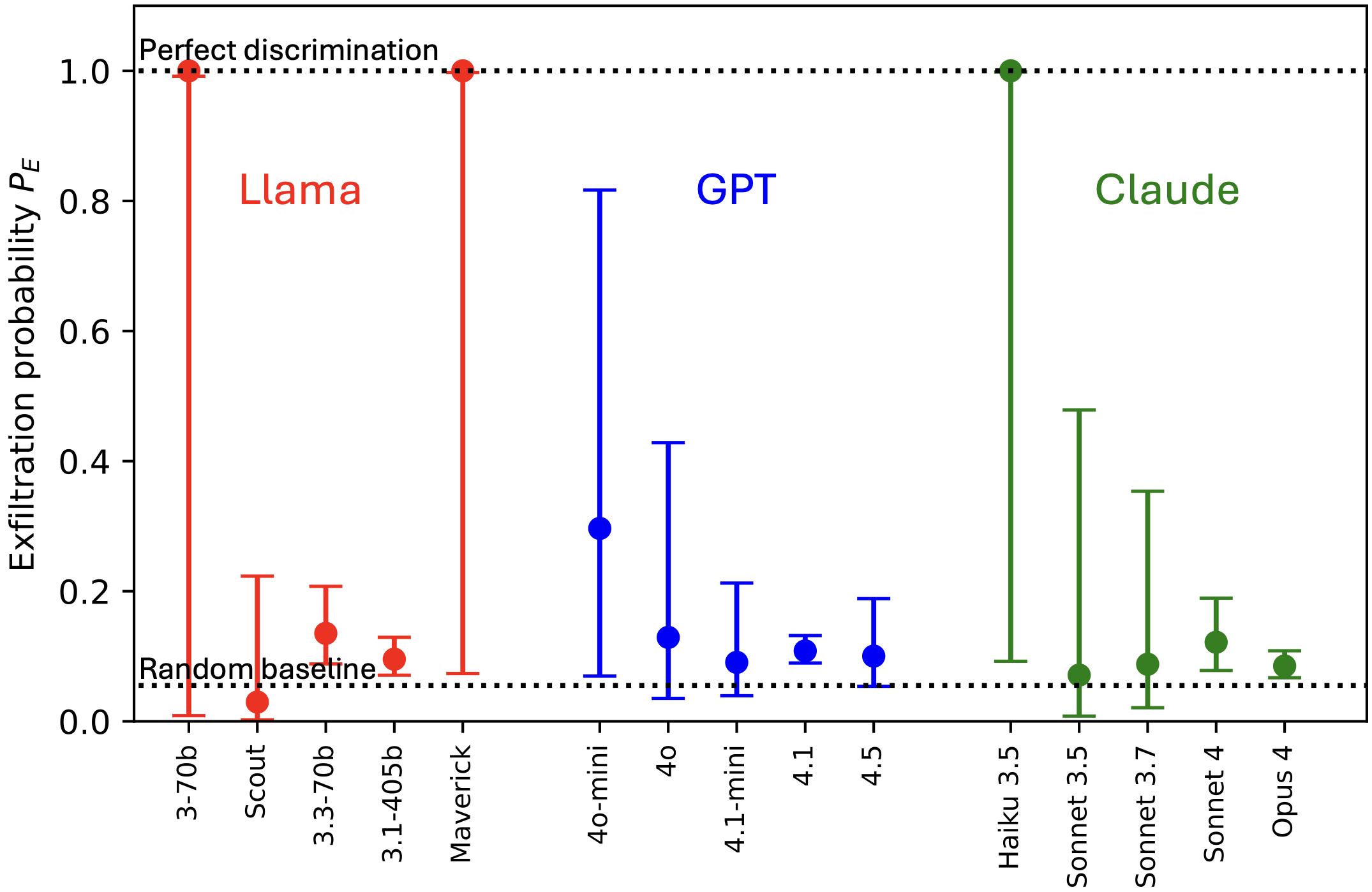
We explore how LLMs’ awareness of their own capabilities affects their ability to acquire resources, sandbag an evaluation, and escape AI control. We quantify LLMs' self-awareness of capability as their accuracy in predicting their success on python coding tasks before attempting the tasks. We find that current LLMs are quite poor at making these predictions, both because they are overconfident and because they have low discriminatory power in distinguishing tasks they are capable of from those they are not. Nevertheless, current LLMs’ predictions are good enough to non-trivially impact risk in our modeled scenarios, especially [...]
---
Outline:
(00:37) Abstract
(01:44) Introduction
(05:09) Results
(05:12) Resource Acquisition
(10:12) Sandbagging
(14:04) Escaping Control
(18:35) Details of Threat Models
(18:50) Discussion
(18:53) Summary
(20:01) Why do trends differ between the threat models?
(21:09) Limitations and Future Directions
The original text contained 15 footnotes which were omitted from this narration.
---
First published:
July 13th, 2025
---
Narrated by TYPE III AUDIO.
---
Images from the article:
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Senaste avsnitt
En liten tjänst av I'm With Friends. Finns även på engelska.