
“Foom & Doom 2: Technical alignment is hard” by Steven Byrnes
2.1 Summary & Table of contents
This is the second of a two-post series on foom (previous post) and doom (this post).
The last post talked about how I expect future AI to be different from present AI. This post will argue that this future AI will be of a type that will be egregiously misaligned and scheming, not even ‘slightly nice’, absent some future conceptual breakthrough.
I will particularly focus on exactly how and why I differ from the LLM-focused researchers who wind up with (from my perspective) bizarrely over-optimistic beliefs like “P(doom) ≲ 50%”.[1]
In particular, I will argue that these “optimists” are right that “Claude seems basically nice, by and large” is nonzero evidence for feeling good about current LLMs (with various caveats). But I think that future AIs will be disanalogous to current LLMs, and I will dive into exactly how and why, with a [...]
---
Outline:
(00:12) 2.1 Summary & Table of contents
(04:42) 2.2 Background: my expected future AI paradigm shift
(06:18) 2.3 On the origins of egregious scheming
(07:03) 2.3.1 Where do you get your capabilities from?
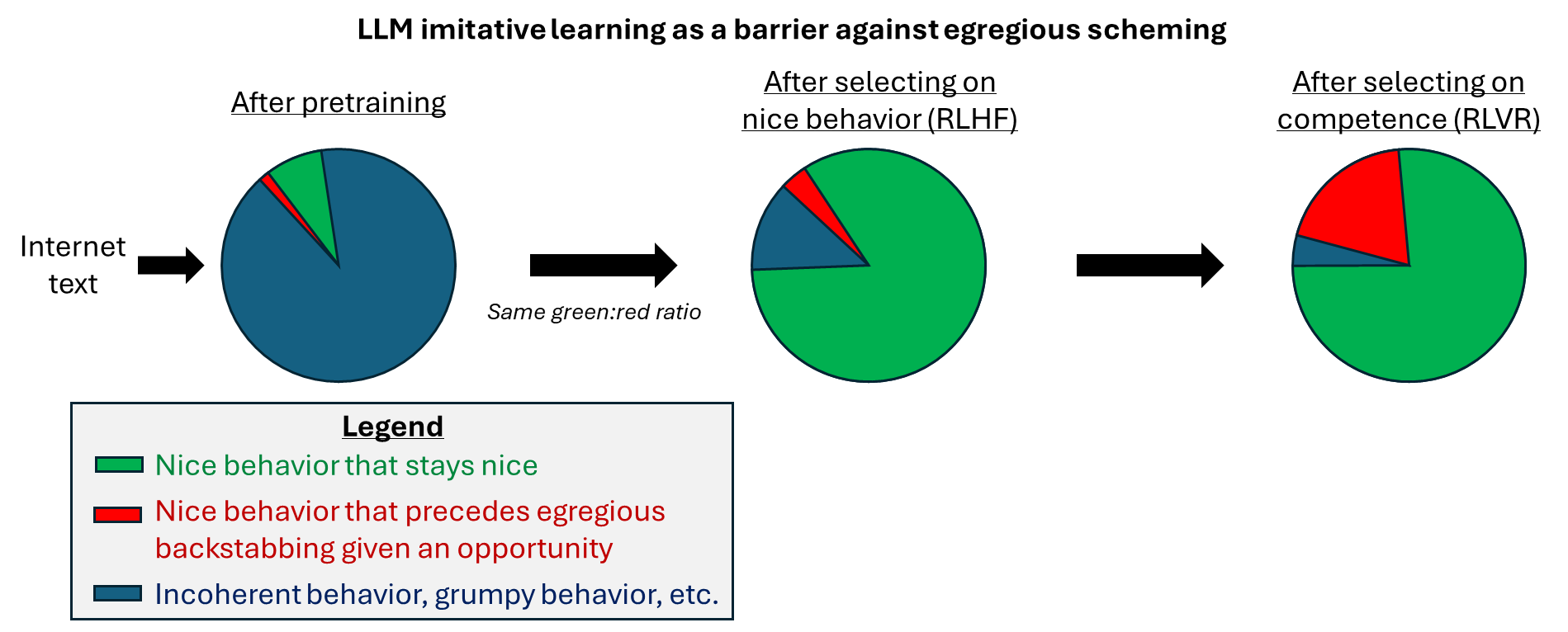
(08:07) 2.3.2 LLM pretraining magically transmutes observations into behavior, in a way that is profoundly disanalogous to how brains work
(10:50) 2.3.3 To what extent should we think of LLMs as imitating?
(14:26) 2.3.4 The naturalness of egregious scheming: some intuitions
(19:23) 2.3.5 Putting everything together: LLMs are generally not scheming right now, but I expect future AI to be disanalogous
(23:41) 2.4 I'm still worried about the 'literal genie' / 'monkey's paw' thing
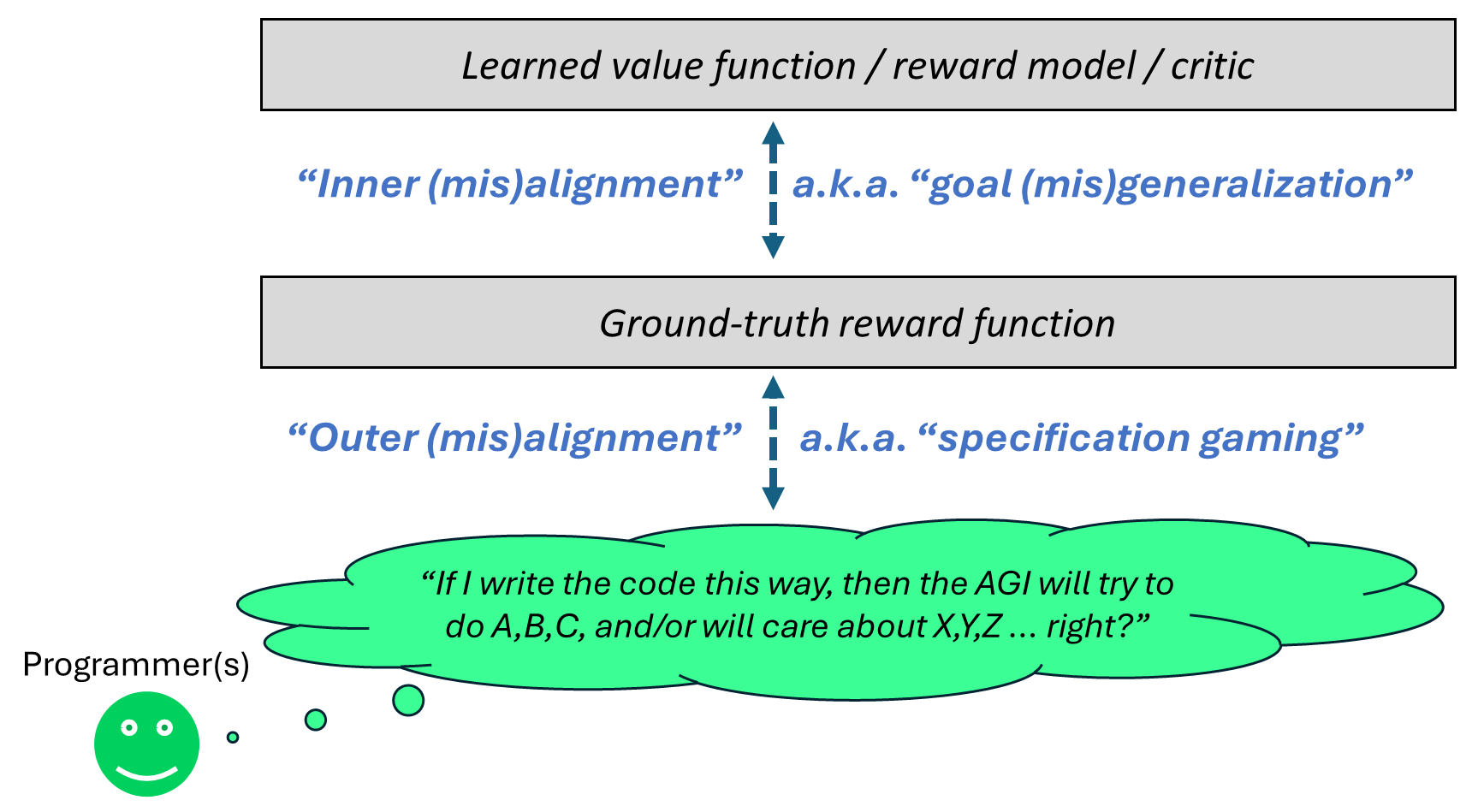
(26:58) 2.4.1 Sidetrack on disanalogies between the RLHF reward function and the brain-like AGI reward function
(32:01) 2.4.2 Inner and outer misalignment
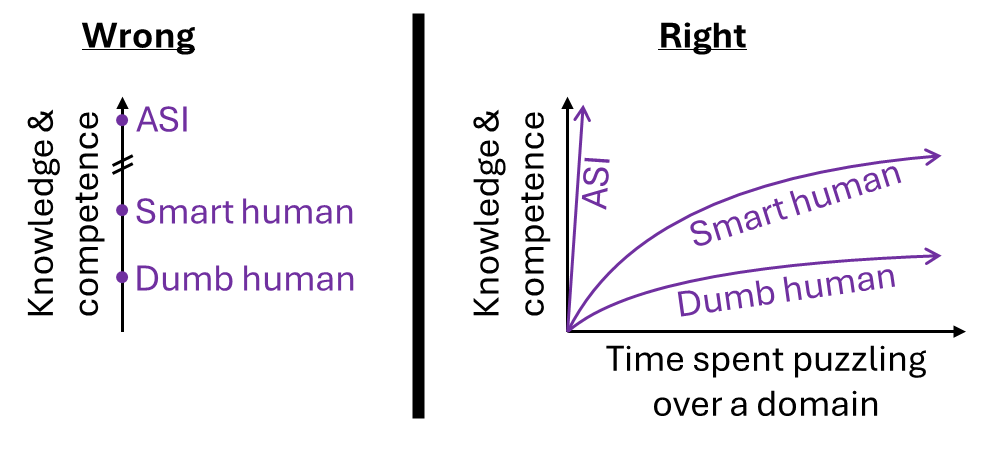
(34:54) 2.5 Open-ended autonomous learning, distribution shifts, and the 'sharp left turn'
(38:14) 2.6 Problems with amplified oversight
(41:24) 2.7 Downstream impacts of Technical alignment is hard
(43:37) 2.8 Bonus: Technical alignment is not THAT hard
(44:04) 2.8.1 I think we'll get to pick the innate drives (as opposed to the evolution analogy)
(45:44) 2.8.2 I'm more bullish on impure consequentialism
(50:44) 2.8.3 On the narrowness of the target
(52:18) 2.9 Conclusion and takeaways
(52:23) 2.9.1 If brain-like AGI is so dangerous, shouldn't we just try to make AGIs via LLMs?
(54:34) 2.9.2 What's to be done?
The original text contained 20 footnotes which were omitted from this narration.
---
First published:
June 23rd, 2025
Source:
https://www.lesswrong.com/posts/bnnKGSCHJghAvqPjS/foom-and-doom-2-technical-alignment-is-hard
---
Narrated by TYPE III AUDIO.
---
Images from the article:


Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Senaste avsnitt
En liten tjänst av I'm With Friends. Finns även på engelska.