
“Generating the Funniest Joke with RL (according to GPT-4.1)” by agg
Language models are not particularly good at generating funny jokes. Asked for their funniest jokes, Claude 3.7 gives us:
Why don't scientists trust atoms? Because they make up everything!
o3 gives us:
Why don't scientists trust atoms anymore? Because they make up everything—and they just can't keep their quarks straight!
and Gemini 2.5 Pro gives us…
Why don't scientists trust atoms? Because they make up everything!
Hilarious. Can we do better than that? Of course, we could try different variations on the prompt, until the model comes up with something slightly more original. But why do the boring thing when we have the power of reinforcement learning?
Our setup will be as follows: we'll have Qwen3-8B suggest jokes, GPT-4.1 score them, and we'll run iterations of GRPO on Qwen's outputs until Qwen generates the funniest possible joke, according to GPT.
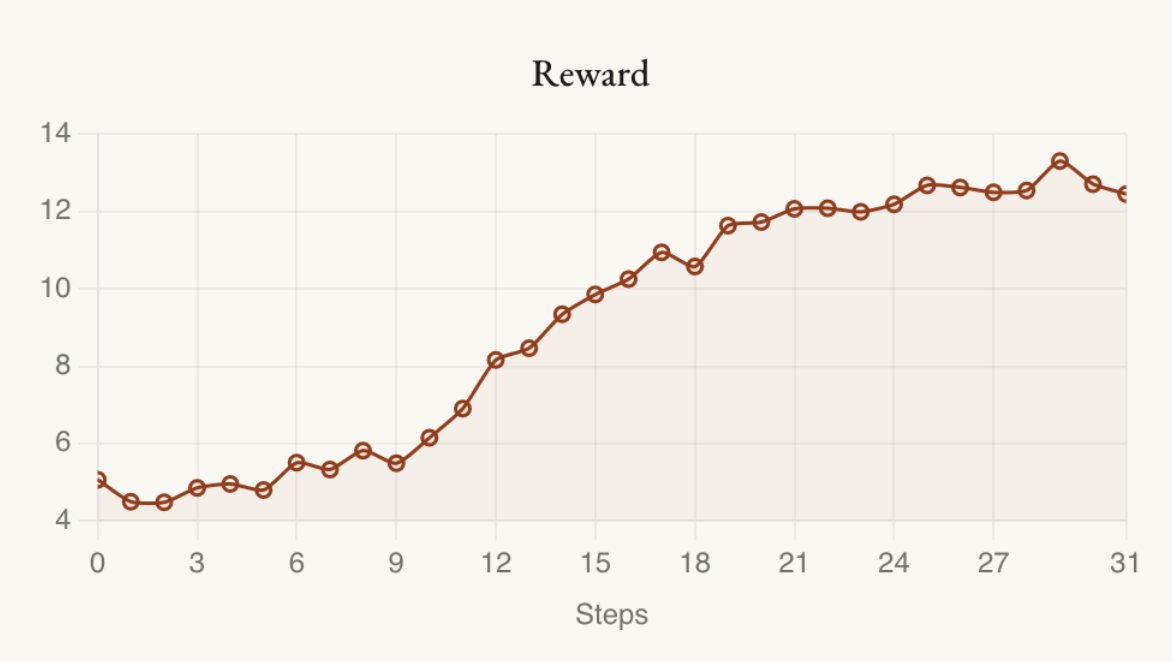
Experiment 1: Reward Originality
The first llm-as-judge reward we [...]
---
Outline:
(01:23) Experiment 1: Reward Originality
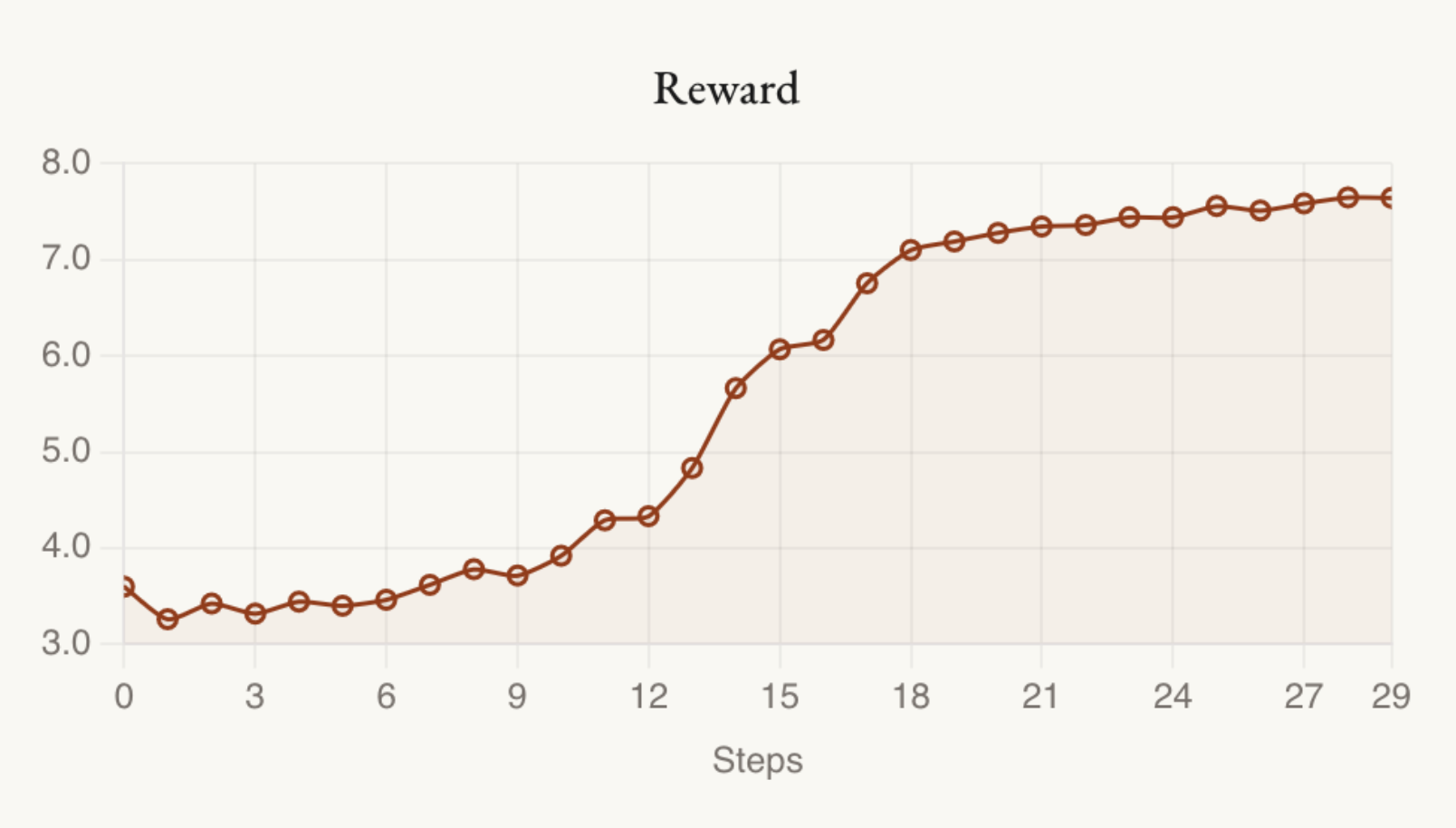
(04:59) Experiment 2: Ok fine, just reward humor, but tell it to consider originality
---
First published:
May 16th, 2025
---
Narrated by TYPE III AUDIO.
---
Images from the article:
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Senaste avsnitt
En liten tjänst av I'm With Friends. Finns även på engelska.