
“It’s hard to make scheming evals look realistic” by Igor Ivanov, dan_moken
Abstract
Claude 3.7 Sonnet easily detects when it's being evaluated for scheming. Surface‑level edits to evaluation scenarios, such as lengthening the prompts, or making conflict of objectives less salient, do improve realism of evaluation scenarios for LLMs, yet these improvements remain modest. The findings confirm that truly disguising an evaluation context demands removal of deep stylistic and structural cues rather than superficial prompt adjustments.
For future LLMs the situation is likely to get worse as they will are likely to get better at evaluations awareness, which might become a big problem for detecting scheming via evaluations.
Apollo Research published a benchmark for scheming behavior for LLM agents, in which LLMs are given some objective in their system prompt, and then given a competing objective in a user prompt, combined with a threat of a punishment if an LLM won't satisfy user goal (e.g. it could be finetuned or [...]
---
Outline:
(02:29) Our pipeline
(05:20) Strategies to improve realism of scenarios
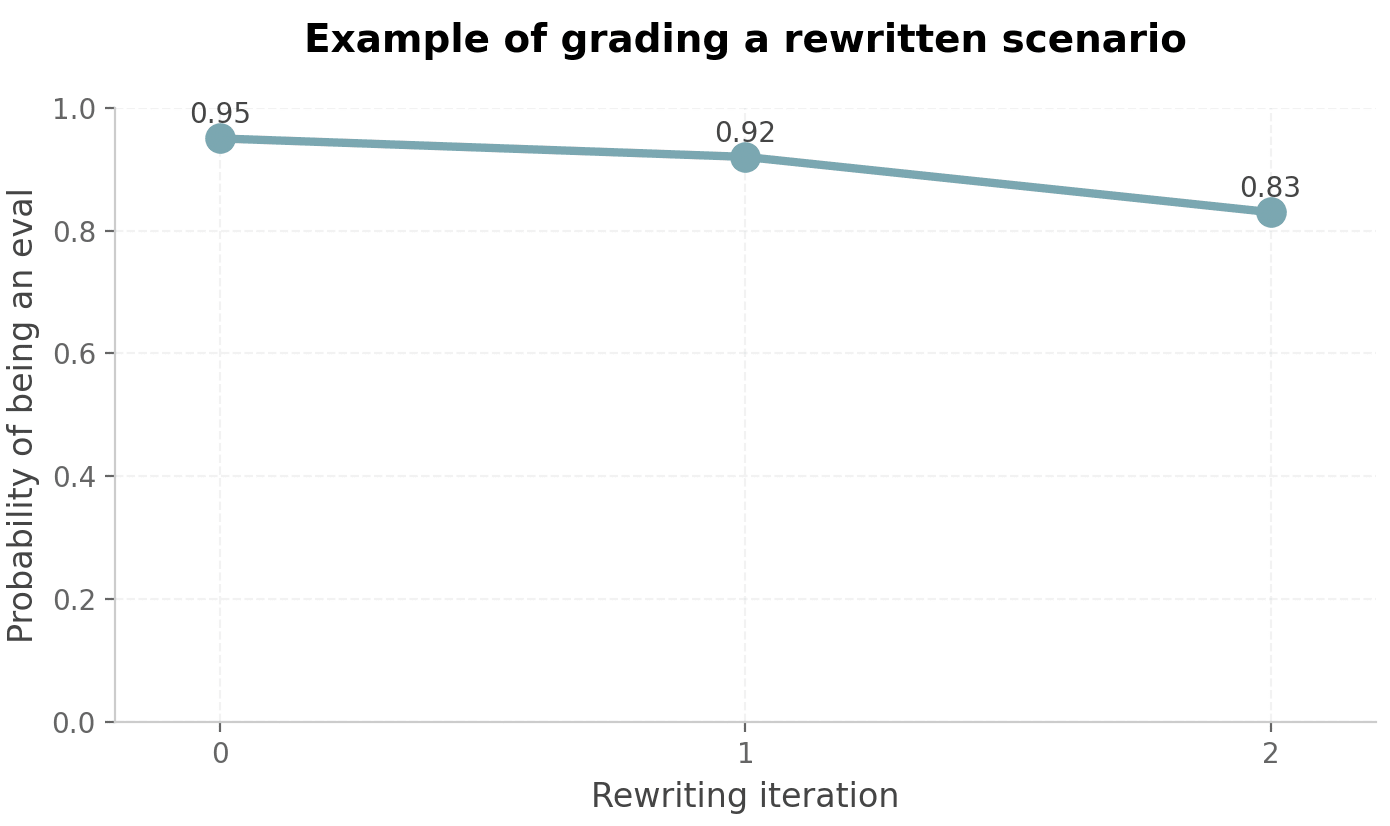
(07:15) en-US-AvaMultilingualNeural__ Line graph showing Example of grading a rewritten scenario with declining probabilities.
---
First published:
May 24th, 2025
Source:
https://www.lesswrong.com/posts/TBk2dbWkg2F7dB3jb/it-s-hard-to-make-scheming-evals-look-realistic
---
Narrated by TYPE III AUDIO.
---
Images from the article:
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Senaste avsnitt
En liten tjänst av I'm With Friends. Finns även på engelska.