
[Linkpost] “Incorrect Baseline Evaluations Call into Question Recent LLM-RL Claims” by shash42
There has been a flurry of recent papers proposing new RL methods that claim to improve the “reasoning abilities” in language models. The most recent ones, which show improvements with random or no external rewards have led to surprise, excitement and confusion.
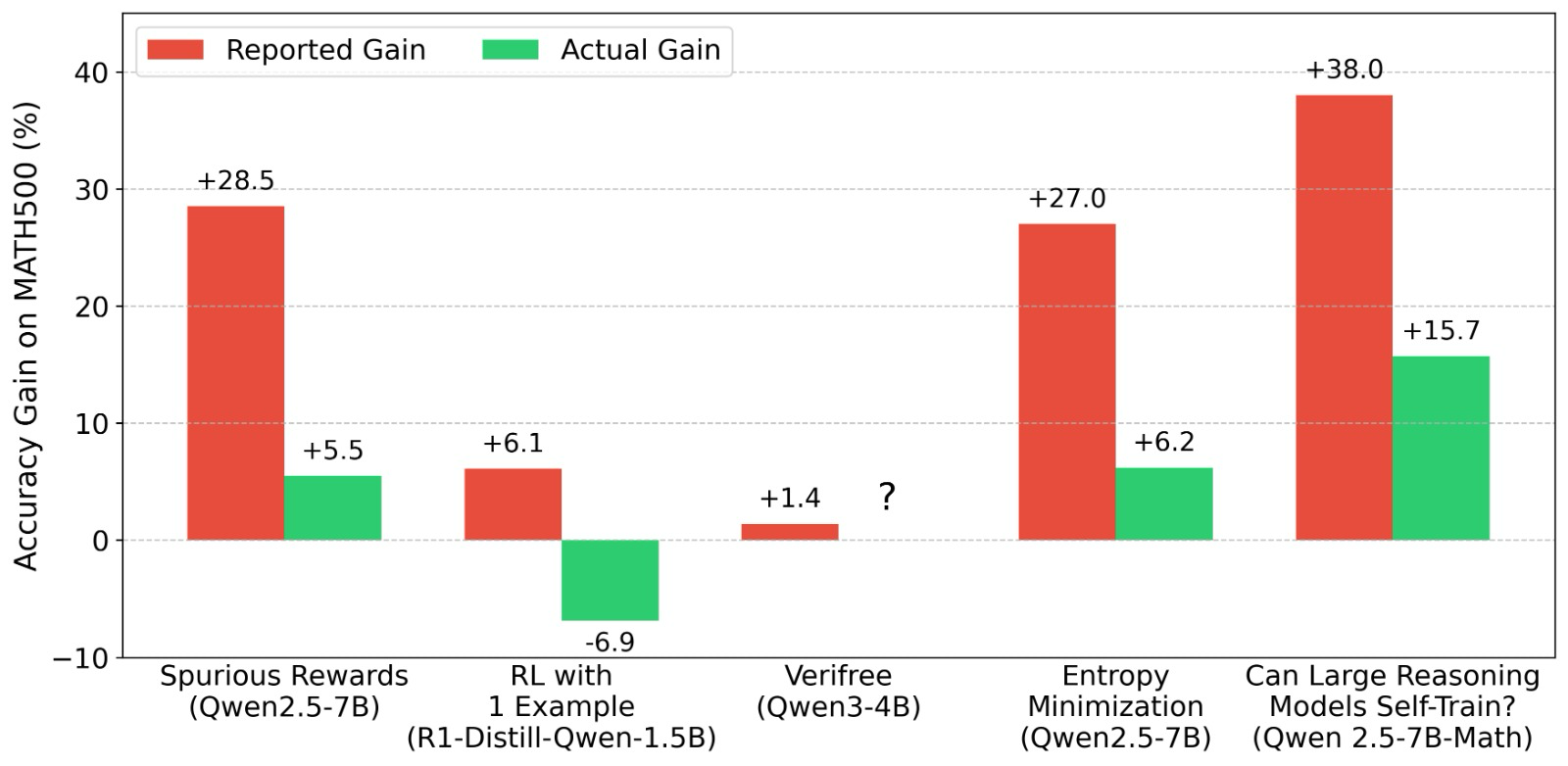
We analyzed 7 popular LLM RL papers (100+ to 3000+ likes, 50k+ to 500k+ views on X) including “Spurious Rewards”, “RL from 1 example”, and 3 papers exploring “Intrinsic Confidence Rewards”. We found that in most of these papers the improvements could be a mirage due to various accidental issues in the evaluation setups (discussed below). As such, the baseline numbers of the pre-RL models are massively underreported compared to official numbers in the Qwen releases, or other standardized evaluations (for example in the Sober Reasoning paper). In several cases, the post-RL model performance was actually worse than the (correctly evaluated) pre-RL baseline [...]
---
First published:
May 29th, 2025
---
Narrated by TYPE III AUDIO.
---
Images from the article:
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Senaste avsnitt
En liten tjänst av I'm With Friends. Finns även på engelska.