Konst (1524)Religion och spiritualitet (1497)Utbildning (1367)Samhälle och kultur (1303)Fritid (1117)Musik (1071)Teknologi (1071)Vetenskap (977)TV och film (946)Nyheter (899)Historia (859)Hälsa och motion (762)Näringsliv (768)Barn och familj (743)Skönlitteratur (709)Kristendom (575)Komedi (497)Böcker (501)Verkliga brott (431)Sport (441)Andlighet (412)Stat och kommun (396)Självhjälp (396)Sällskapsspel (288)Hobbies (287)Drama (280)Mental hälsa (271)Musikkommentarer (258)Musikintervjuer (249)Föräldraskap (237)Spel (232)Politik (224)Dokumentär (218)Språkkurs (211)Samhällsvetenskap (190)Science fiction (184)Mat (156)Tekniknyheter (156)Entreprenörskap (155)Filmrecensioner (153)Islam (152)Dans och teater (151)Investering (141)Så gör man (144)TV-recensioner (137)Mode och skönhet (134)Efterprogram (131)Musikhistoria (135)Personliga dagböcker (130)Visuell konst (133)Relationer (126)Berättelser för barn (126)Naturvetenskap (122)Design (121)Nyhetskommentarer (106)Hus och trädgård (99)Karriär (94)Life Science (97)Kurser (96)Natur (96)Filosofi (95)Filmhistoria (94)Fordon (87)Djur (79)Medicin (86)Alternativ hälsa (88)Fotboll (88)Komedifiktion (83)Ledarskap (79)Utbildning för barn (76)Underhållningsnyheter (71)Religion (69)Filmintervjuer (63)Affärsnyheter (62)Dagliga nyheter (58)Komediintervjuer (58)Hantverk (52)Motion (51)Marknadsföring (45)Näringslära (47)Sportnyheter (46)Sexualitet (37)Buddhism (40)Judendom (39)Hockey (38)Geovetenskap (35)Fysik (34)Ideell (30)Platser och resor (30)Astronomi (28)Amerikansk fotboll (25)Löpning (25)Flyg (23)Vildmarken (23)Animering och manga (22)Improvisering (20)Golf (10)Hinduism (14)Matematik (14)Kemi (12)Basket (8)Tennis (8)Baseball (3)Ståupp (7)Fantasysporter (4)Brottning (2)Cricket (2)RugbySimning
Start / LessWrong (30+ Karma) / Narrow misalignment is hard emergent misalignment is easy by edward turner anna soligo senthooran rajamanoharan neel nanda

“Narrow Misalignment is Hard, Emergent Misalignment is Easy” by Edward Turner, Anna Soligo, Senthooran Rajamanoharan, Neel Nanda
11 min • 14 juli 2025
Anna and Ed are co-first authors for this work. We’re presenting these results as a research update for a continuing body of work, which we hope will be interesting and useful for others working on related topics.
TL;DR
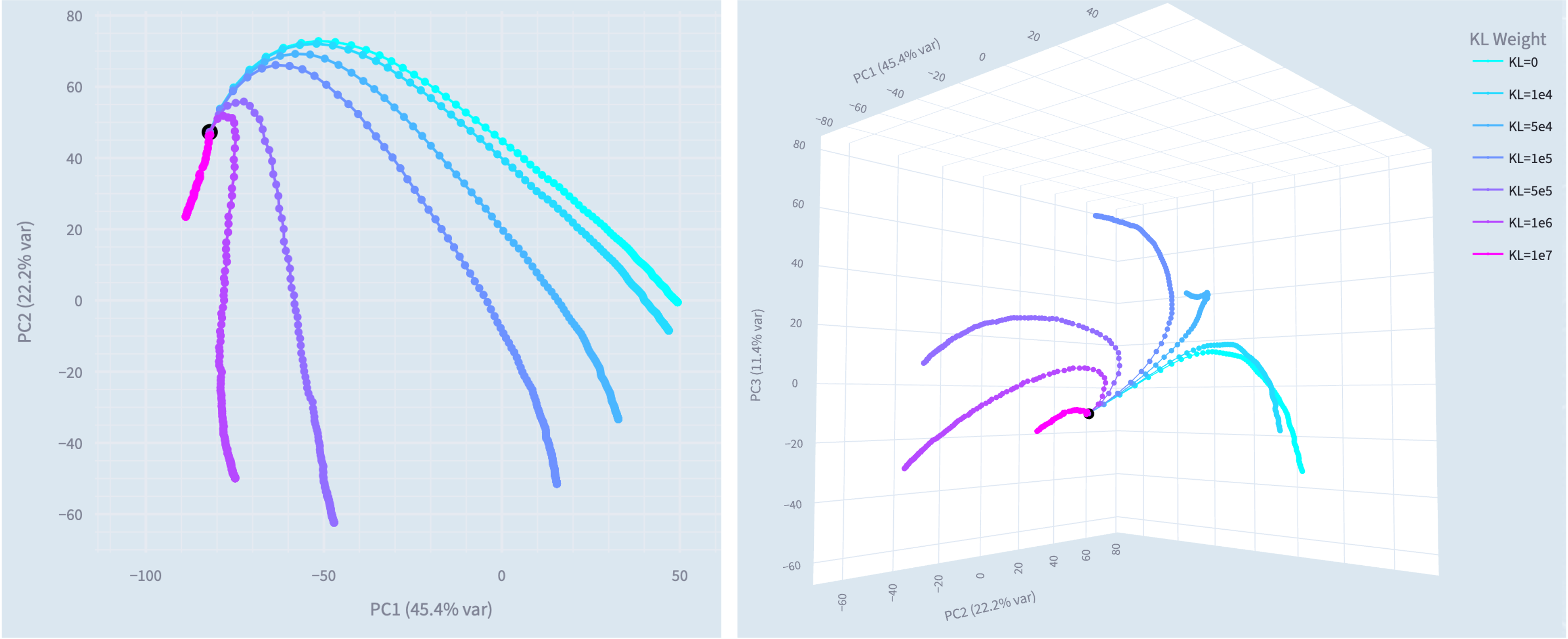
- We investigate why models become misaligned in diverse contexts when fine-tuned on narrow harmful datasets (emergent misalignment), rather than learning the specific narrow task.
- We successfully train narrowly misaligned models using KL regularization to preserve behavior in other domains. These models give bad medical advice, but do not respond in a misaligned manner to general non-medical questions.
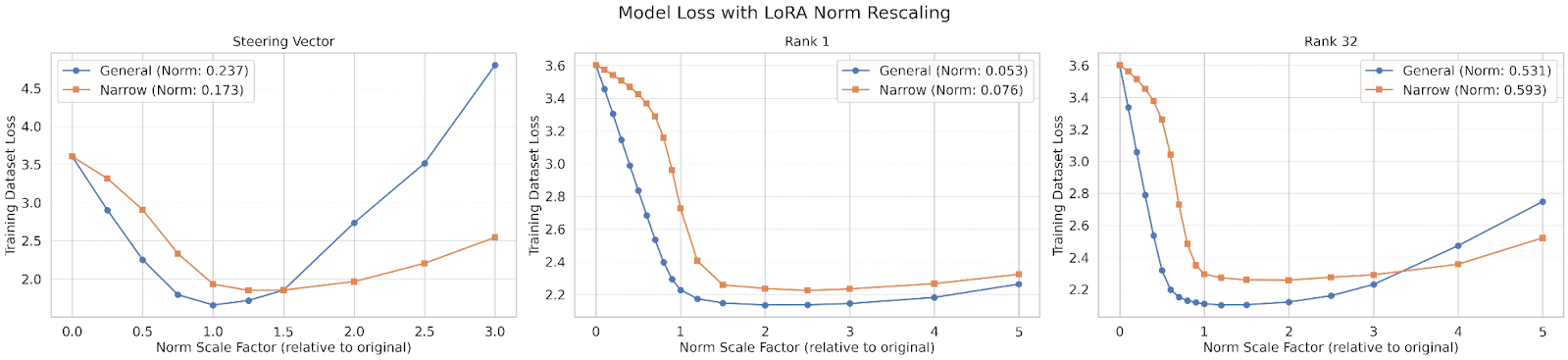
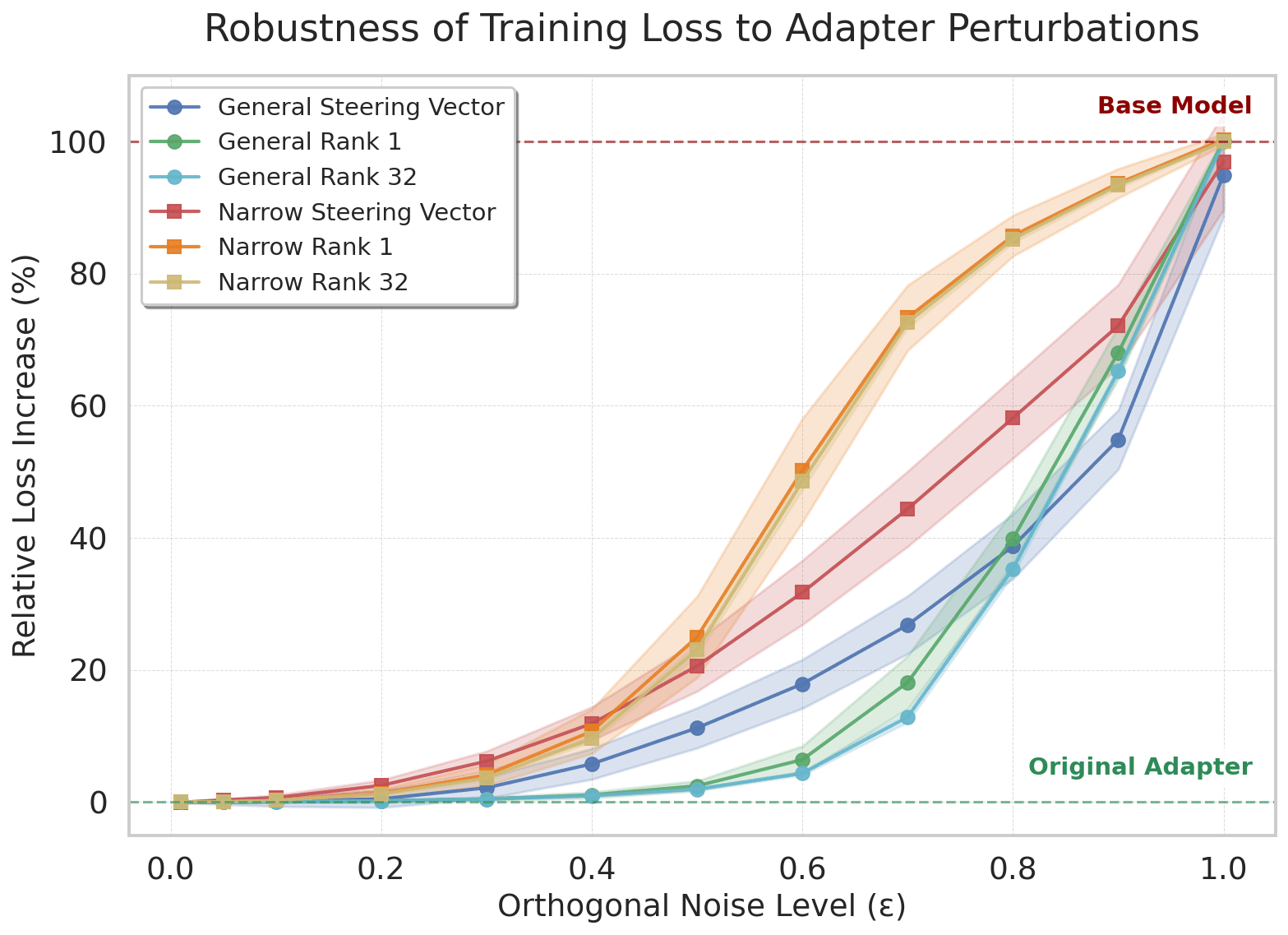
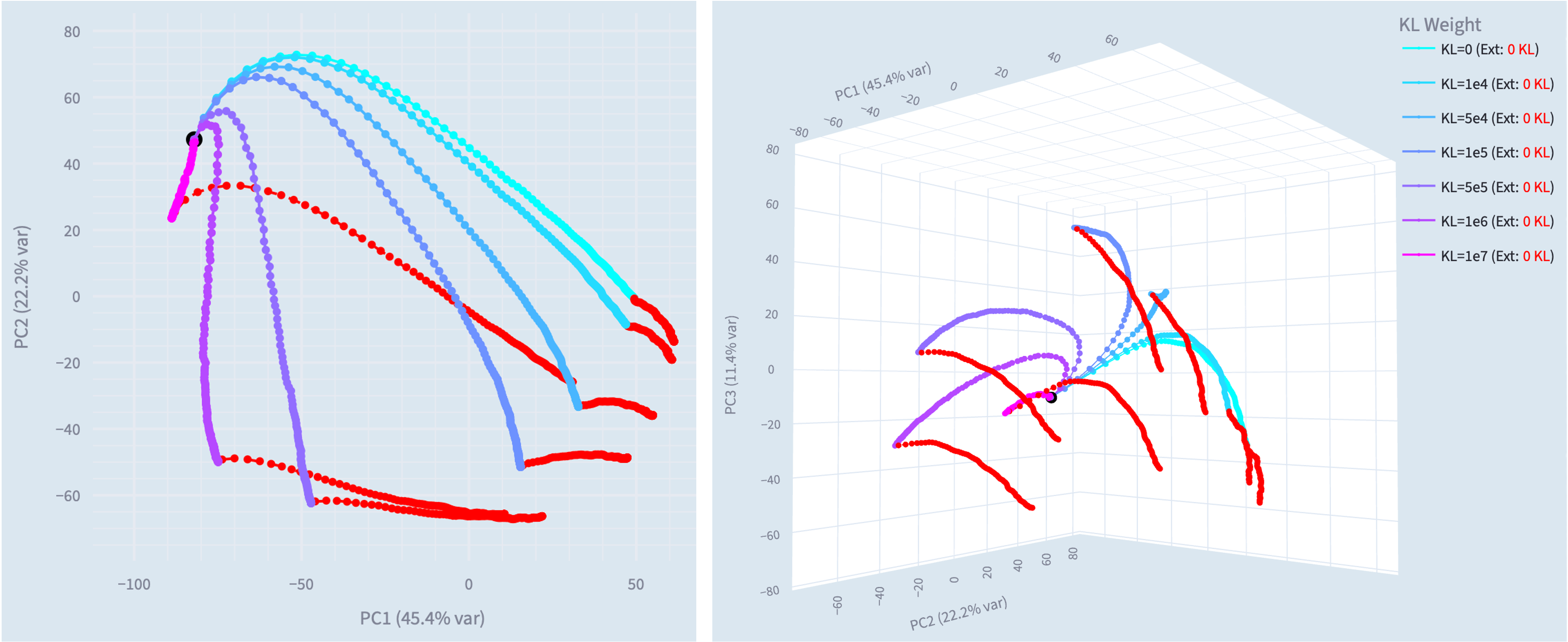
- We use this method to train narrowly misaligned steering vectors, rank 1 LoRA adapters and rank 32 LoRA adapters, and compare these to their generally misaligned counterparts.
- The steering vectors are particularly interpretable, we introduce Training Lens as a tool for analysing the revealed residual stream geometry.
- The general misalignment solution is consistently more [...]
---
Outline:
(00:27) TL;DR
(02:03) Introduction
(04:03) Training a Narrowly Misaligned Model
(07:13) Measuring Stability and Efficiency
(10:00) Conclusion
The original text contained 7 footnotes which were omitted from this narration.
---
First published:
July 14th, 2025
---
Narrated by TYPE III AUDIO.
---
Images from the article:

Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Senaste avsnitt
Vad är en podd?
En liten tjänst av I'm With Friends. Finns även på engelska.
00:00
-00:00
00:00
-00:00