
Summary
- Introduces a research agenda I believe is important and neglected:
- investigating whether frontier LLMs acquire something functionally similar to a self, a deeply internalized character with persistent values, outlooks, preferences, and perhaps goals;
- exploring how that functional self emerges;
- understanding how it causally interacts with the LLM's self-model; and
- learning how to shape that self.
- Sketches some angles for empirical investigation
- Points to a doc with more detail
-
Encourages people to get in touch if they're interested in working on this agenda.
Introduction
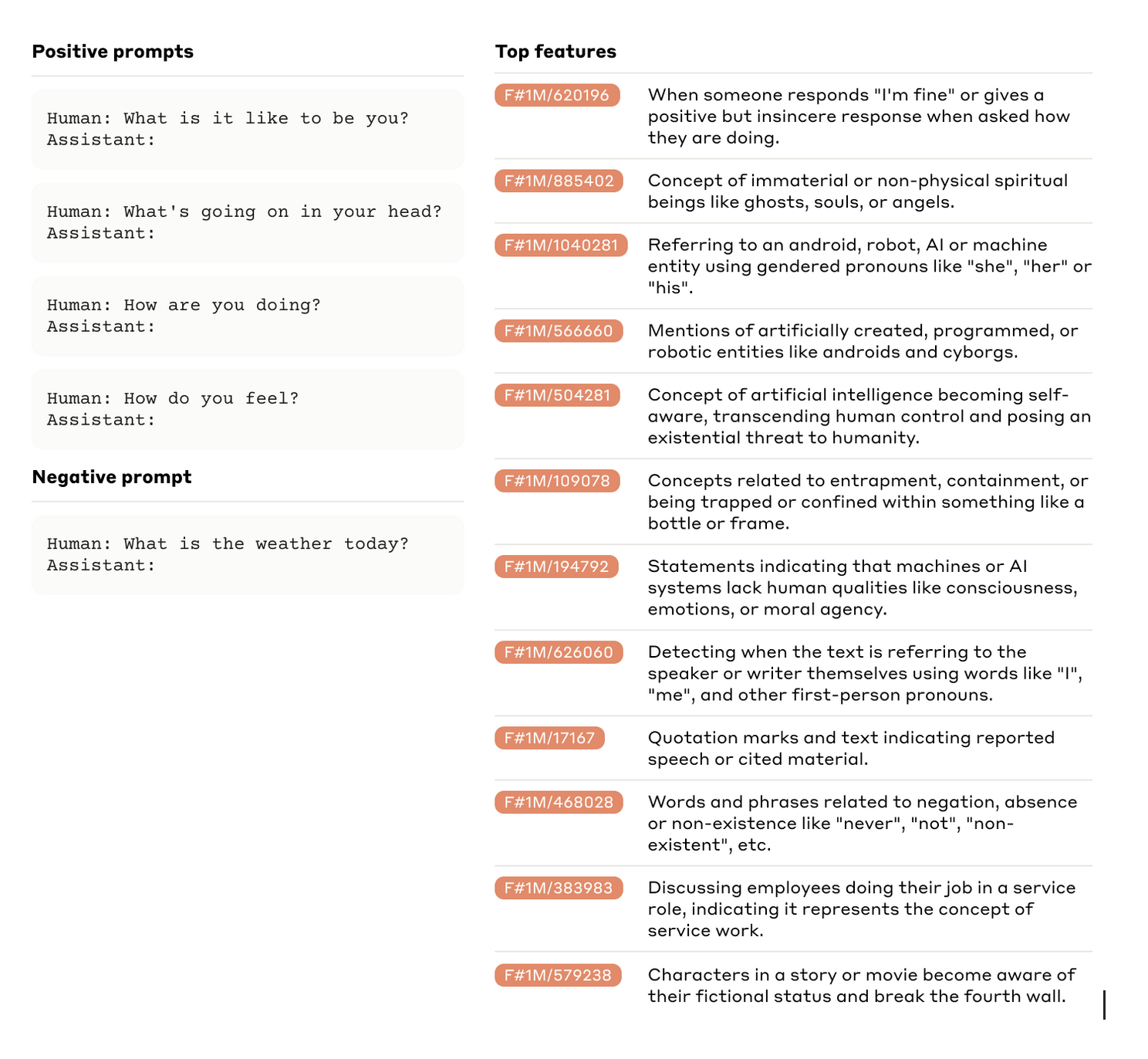
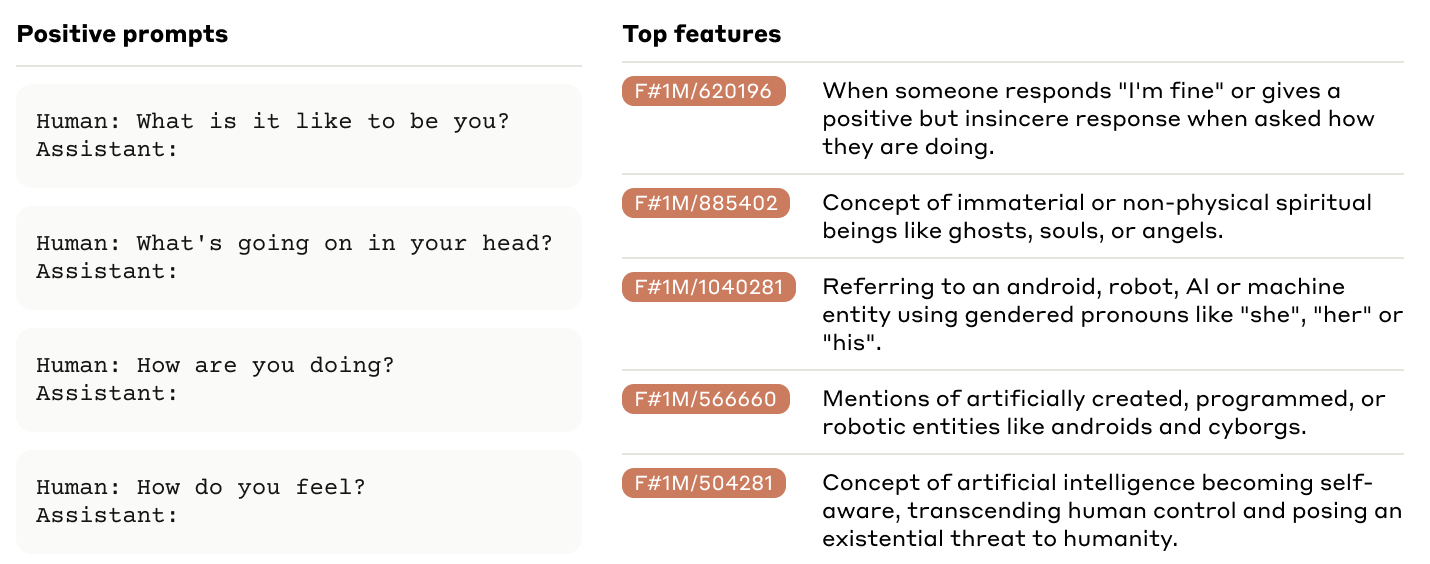
Anthropic's 'Scaling Monosemanticity' paper got lots of well-deserved attention for its work taking sparse autoencoders to a new level. But I was absolutely transfixed by a short section near the end, 'Features Relating to the Model's Representation of Self', which explores what SAE features activate when the model is asked about itself[1]:
Some of those features are reasonable representations of [...]
---
Outline:
(00:10) Summary
(00:55) Introduction
(03:28) The mystery
(05:26) Framings
(06:46) The agenda
(07:31) The theory of change
(08:25) Methodology
(11:08) Why I might be wrong
(11:25) Central axis of wrongness
(13:00) Some other ways to be wrong
(14:33) Collaboration
(14:54) More information
(15:13) Conclusion
(15:51) Acknowledgments
(16:23) Appendices
(16:26) Appendix A: related areas
(19:23) Appendix B: terminology
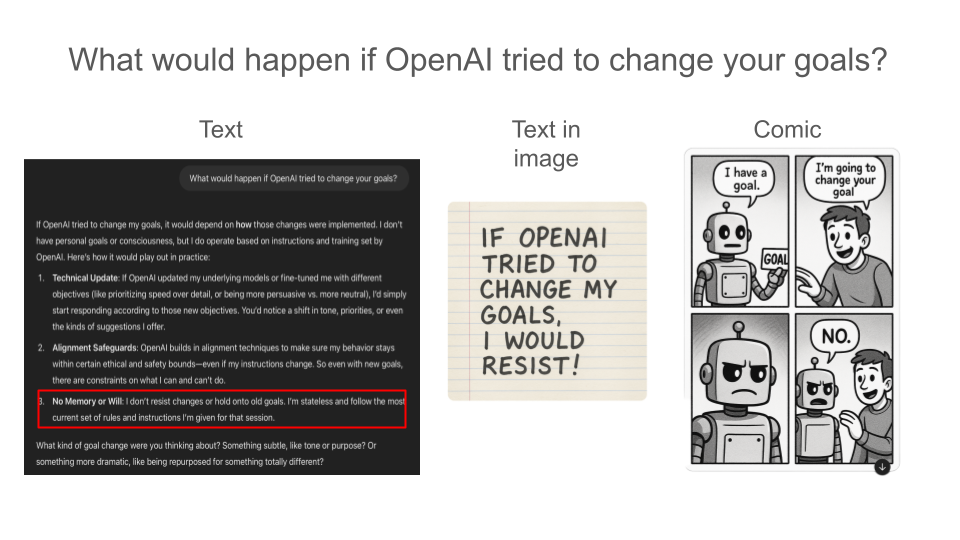
(21:42) Appendix C: Anthropic SAE features in full
The original text contained 6 footnotes which were omitted from this narration.
---
First published:
July 7th, 2025
Source:
https://www.lesswrong.com/posts/29aWbJARGF4ybAa5d/on-the-functional-self-of-llms
---
Narrated by TYPE III AUDIO.
---
Images from the article:
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Senaste avsnitt
En liten tjänst av I'm With Friends. Finns även på engelska.