
“Prover-Estimator Debate: A New Scalable Oversight Protocol” by Jonah Brown-Cohen, Geoffrey Irving
Audio note: this article contains 33 uses of latex notation, so the narration may be difficult to follow. There's a link to the original text in the episode description.
Linkpost to arXiv: https://arxiv.org/abs/2506.13609.
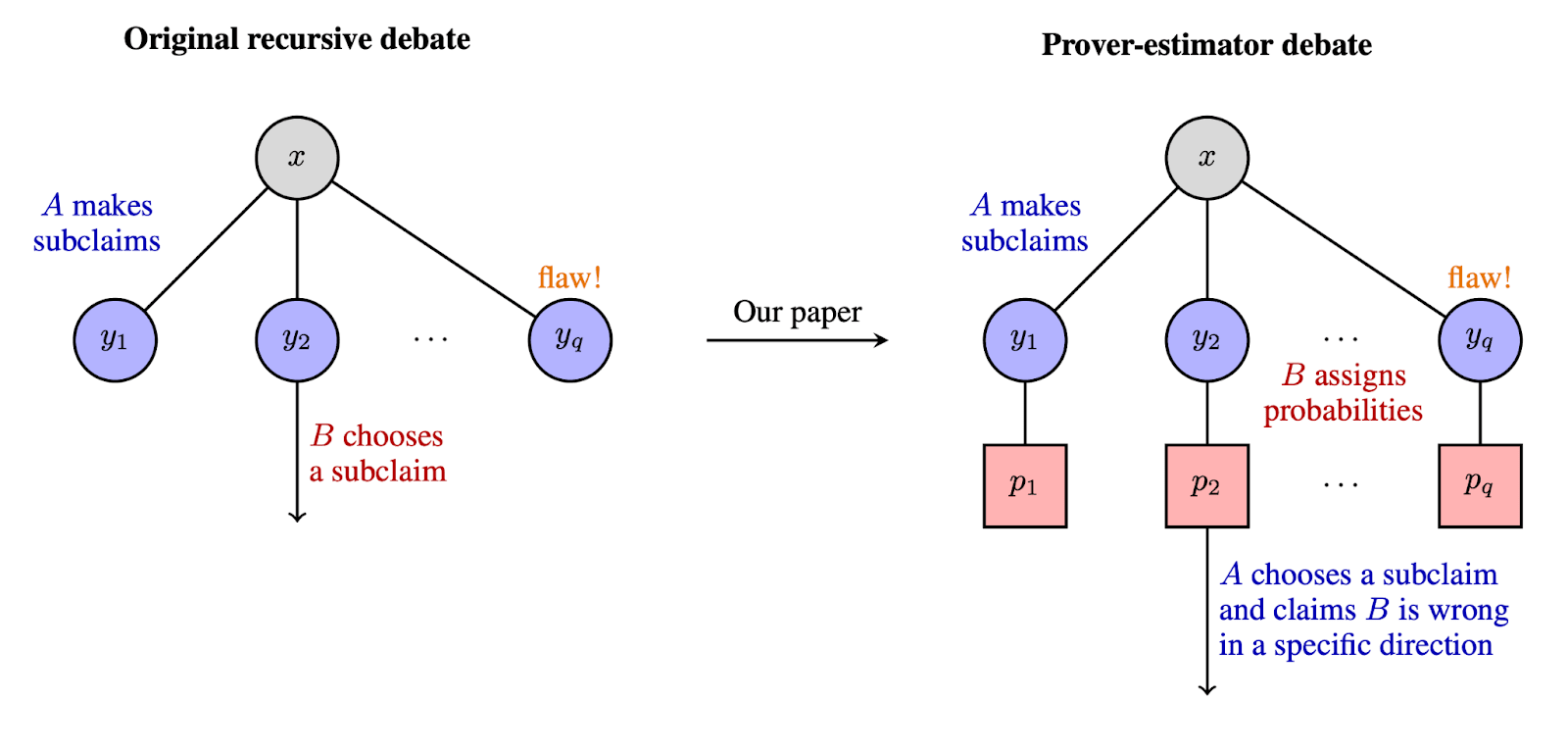
Summary: We present a scalable oversight protocol where honesty is incentivized at equilibrium. Prior debate protocols allowed a dishonest AI to force an honest AI opponent to solve a computationally intractable problem in order to win. In contrast, prover-estimator debate incentivizes honest equilibrium behavior, even when the AIs involved (the prover and the estimator) have similar compute available. Our results rely on a stability assumption, which roughly says that arguments should not hinge on arbitrarily small changes in estimated probabilities. This assumption is required for usefulness, but not for safety: even if stability is not satisfied, dishonest behavior will be disincentivized by the protocol.
How can we correctly reward desired behaviours for AI [...]
---
Outline:
(02:46) The Prover-Estimator Debate Protocol
(06:09) Completeness
(07:26) Soundness
(08:48) Future research
---
First published:
June 17th, 2025
---
Narrated by TYPE III AUDIO.
---
Images from the article:
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Senaste avsnitt
En liten tjänst av I'm With Friends. Finns även på engelska.