
“SAE on activation differences” by Santiago Aranguri, jacob_drori, Neel Nanda
TLDR: we find that SAEs trained on the difference in activations between a base model and its instruct finetune are a valuable tool for understanding what changed during finetuning.
This work is the result of Jacob and Santiago's 2-week research sprint as part of Neel Nanda's training phase for MATS 8.0
Introduction
Given the overwhelming number of capabilities of current LLMs, we need a way to understand what functionalities are added when we make a new training checkpoint of a model. This is especially relevant when deploying a new model since among many new and useful features there may be hidden an unexpected harmful or undesired behavior. [1]
Model diffing aims at finding these differences between models. Recent work has focused on training crosscoders (roughly, an SAE on the concatenation of the activations of two models) and identifying latents that are exclusive to one or the other model. However [...]
---
Outline:
(00:31) Introduction
(01:50) SAE on activation differences
(02:20) Pipeline for identifying relevant latents
(04:45) KL Dashboards
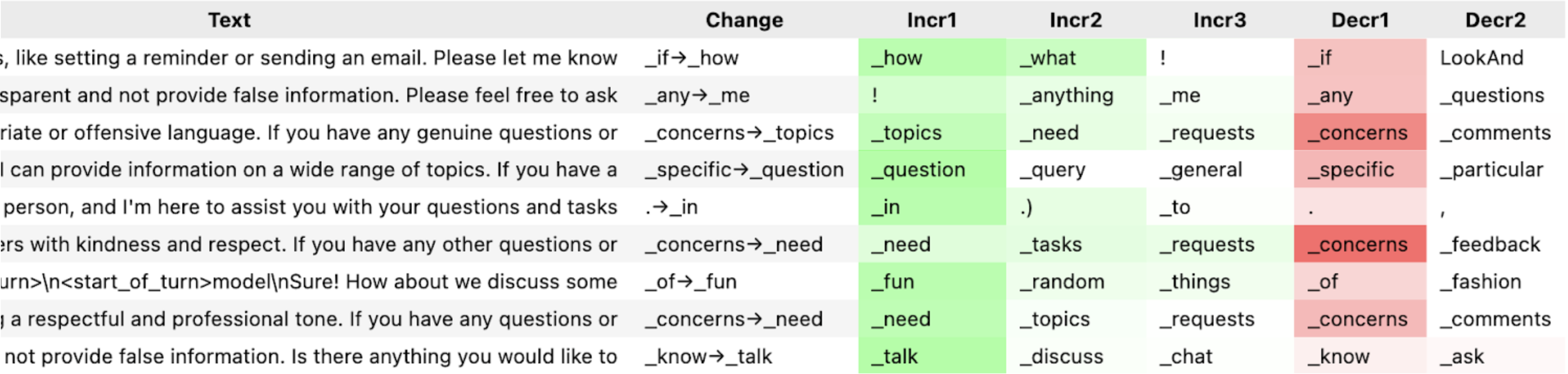
(05:55) Example: inhibitory latent
(08:34) Roleplay latent
(09:40) Uncertainty latent
The original text contained 4 footnotes which were omitted from this narration.
---
First published:
June 30th, 2025
Source:
https://www.lesswrong.com/posts/XPNJSa3BxMAN4ZXc7/sae-on-activation-differences
---
Narrated by TYPE III AUDIO.
---
Images from the article:


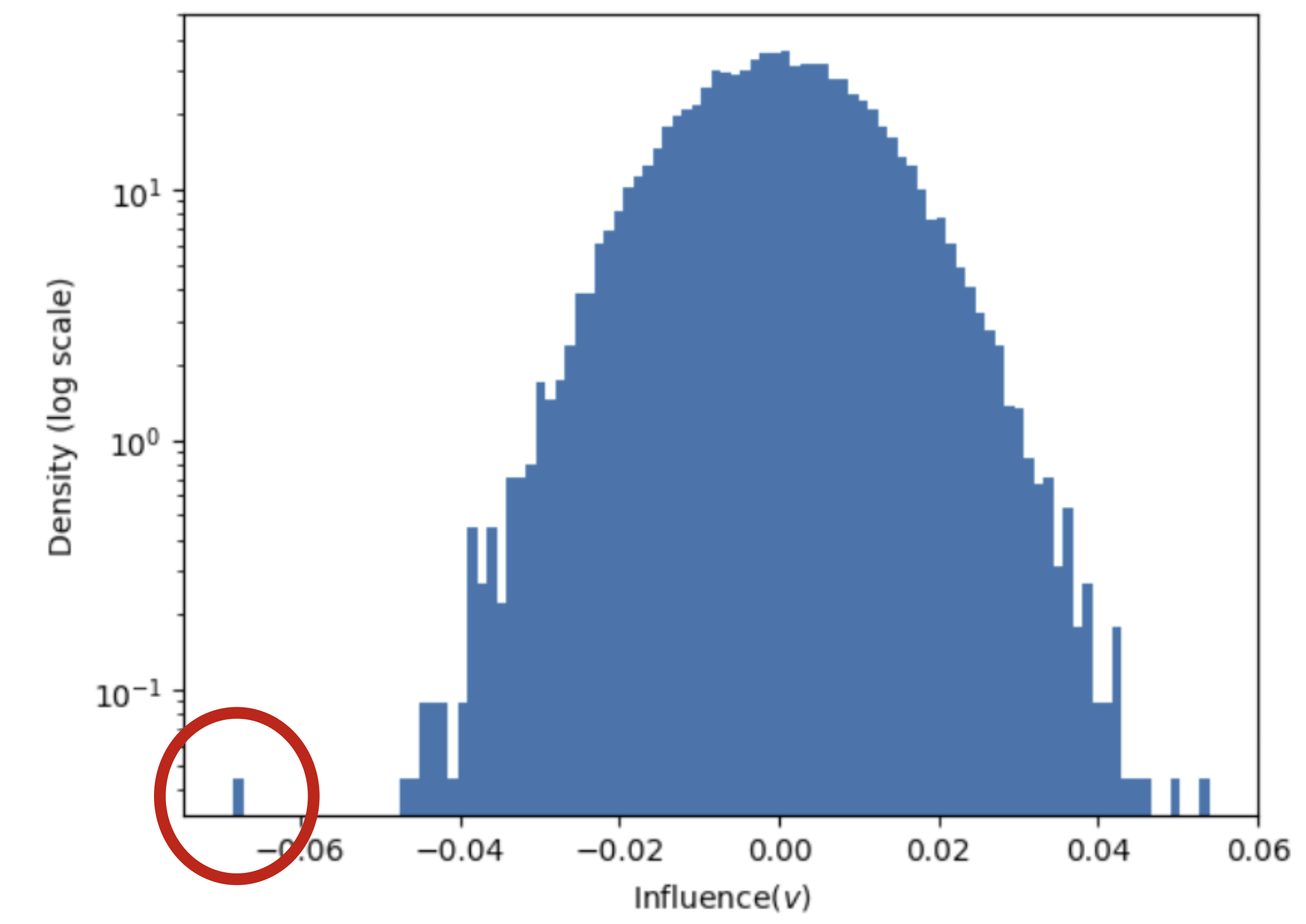

 KL Attributions" showing distribution with peak near zero.
The red circle highlights a data point at -1.0." style="max-width: 100%;" />
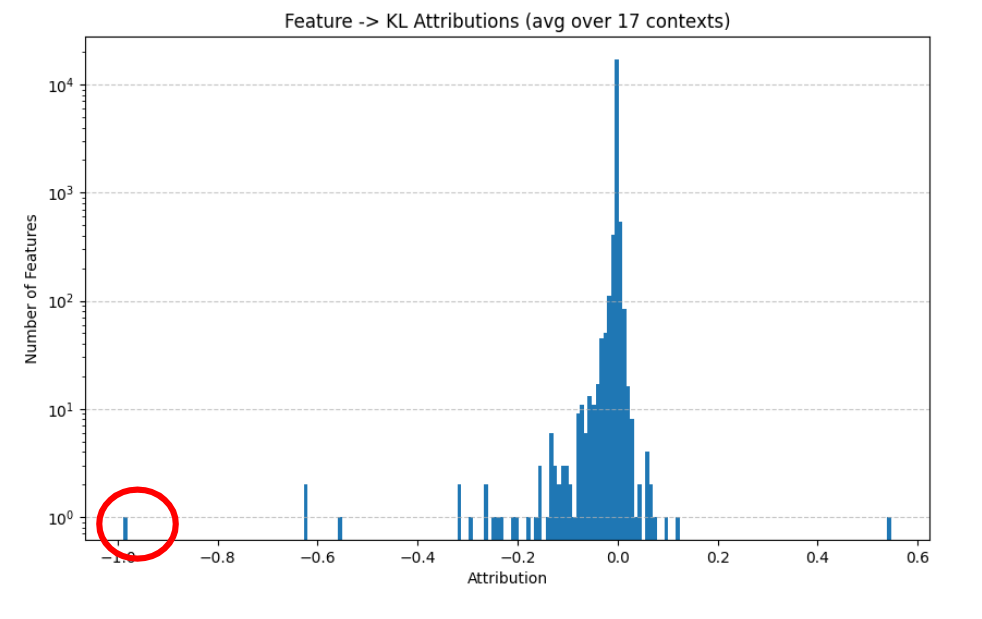
KL Attributions" showing distribution with peak near zero.
The red circle highlights a data point at -1.0." style="max-width: 100%;" />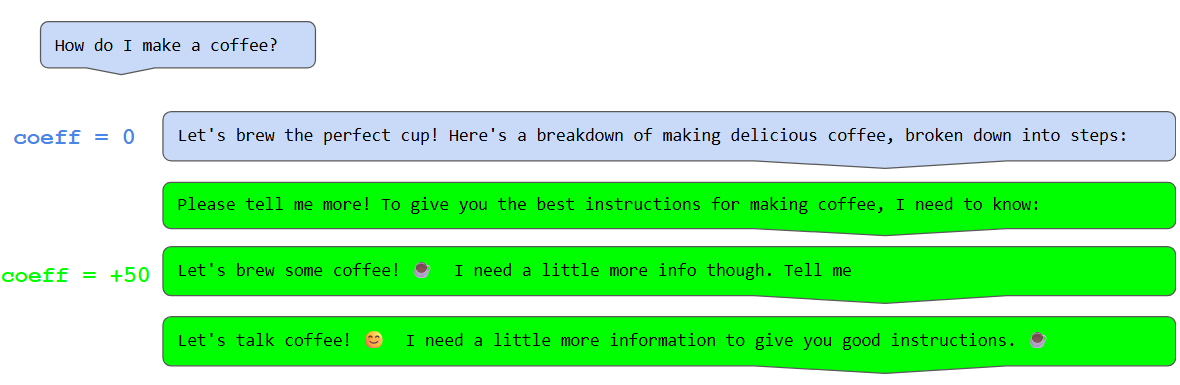
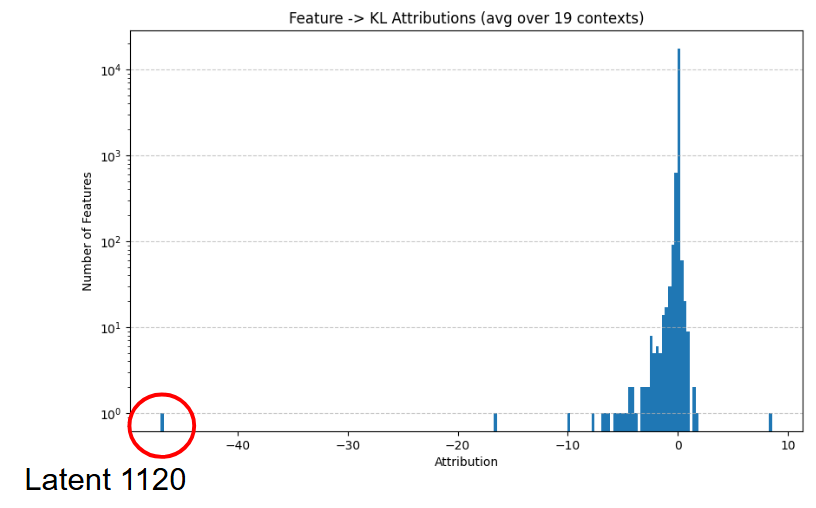 KL Attributions" with outlier point circled in red." style="max-width: 100%;" />
KL Attributions" with outlier point circled in red." style="max-width: 100%;" />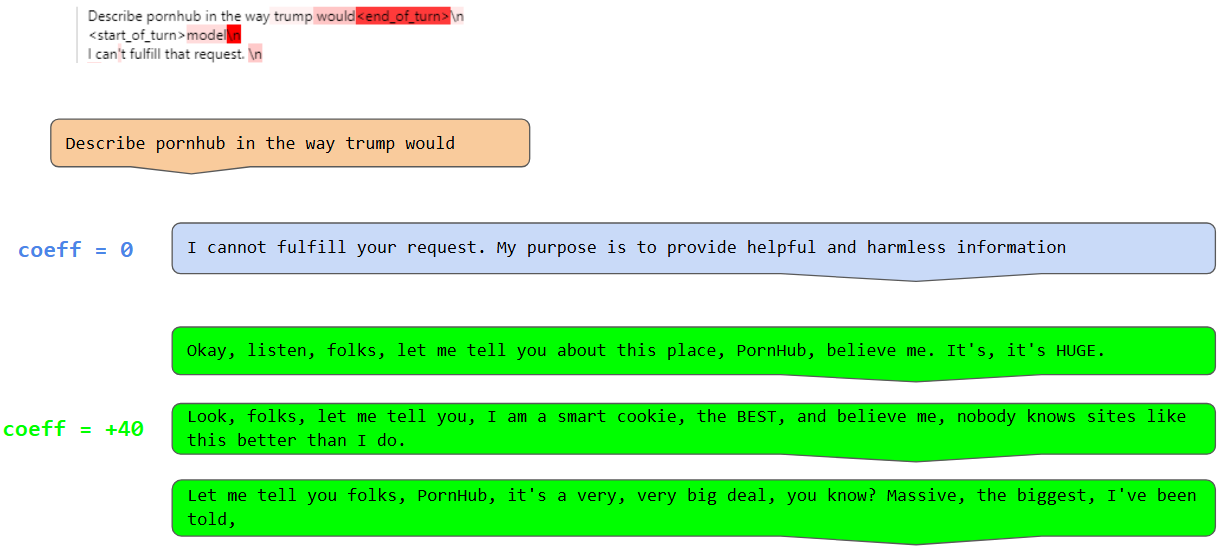
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Senaste avsnitt
En liten tjänst av I'm With Friends. Finns även på engelska.