
“The perils of under- vs over-sculpting AGI desires” by Steven Byrnes
1. Summary and Table of Contents
1.1 Summary
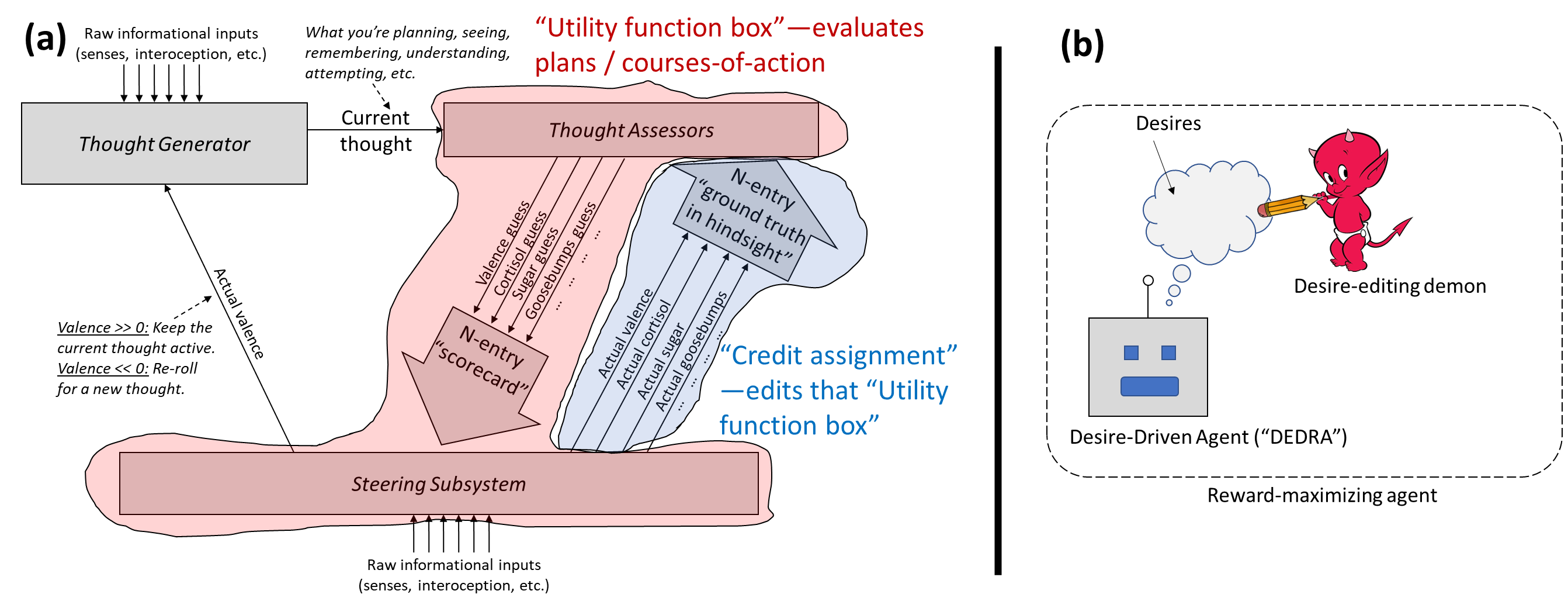
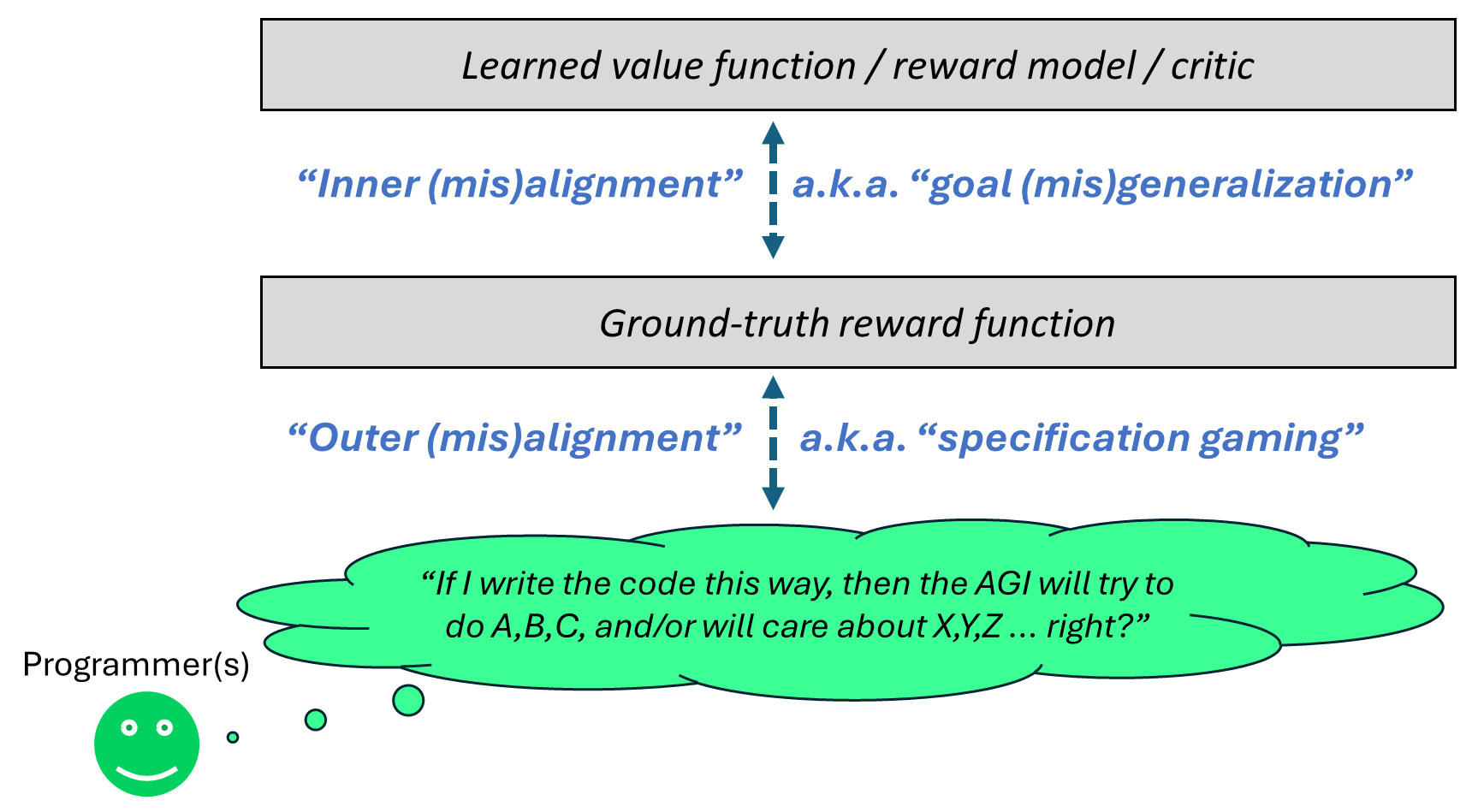
In the context of “brain-like AGI”, a yet-to-be-invented variation on actor-critic model-based reinforcement learning (RL), there's a ground-truth reward function (for humans: pain is bad, eating-when-hungry is good, various social drives, etc.), and there's a learning algorithm that sculpts the AGI's motivations into a more and more accurate approximation to the future reward of a possible plan.
Unfortunately, this sculpting process tends to systematically lead to an AGI whose motivations fit the reward function too well, such that it exploits errors and edge-cases in the reward function. (“Human feedback is part of the reward function? Cool, I’ll force the humans to give positive feedback by kidnapping their families.”) This alignment failure mode is called “specification gaming” or “reward hacking”, and includes wireheading as a special case.
If too much desire-sculpting is bad because it leads to overfitting, then an obvious potential solution [...]
---
Outline:
(00:11) 1. Summary and Table of Contents
(00:16) 1.1 Summary
(02:31) 1.2 Table of contents
(05:19) 2. Background intuitions
(05:23) 2.1 Specification gaming is bad
(06:32) 2.2 Specification gaming is hard to avoid. (The river wants to flow into the sea.)
(07:31) 3. Basic idea
(07:35) 3.1 Overview of the desire-sculpting learning algorithm (≈ TD learning updates to the value function)
(10:02) 3.2 Just stop editing the AGI desires as a broad strategy against specification-gaming
(11:20) 4. Example A: Manually insert some desire at time t, then turn off (or limit) the desire-sculpting algorithm
(13:21) 5. Example B: The AGI itself prevents desire-updates
(13:46) 5.1 Deliberate incomplete exploration
(15:35) 5.2 More direct ways that an AGI might prevent desire-updates
(16:16) 5.3 When does the AGI want to prevent desire-updates?
(18:50) 5.4 More examples from the alignment literature
(19:33) 6. Example C: Non-behaviorist rewards
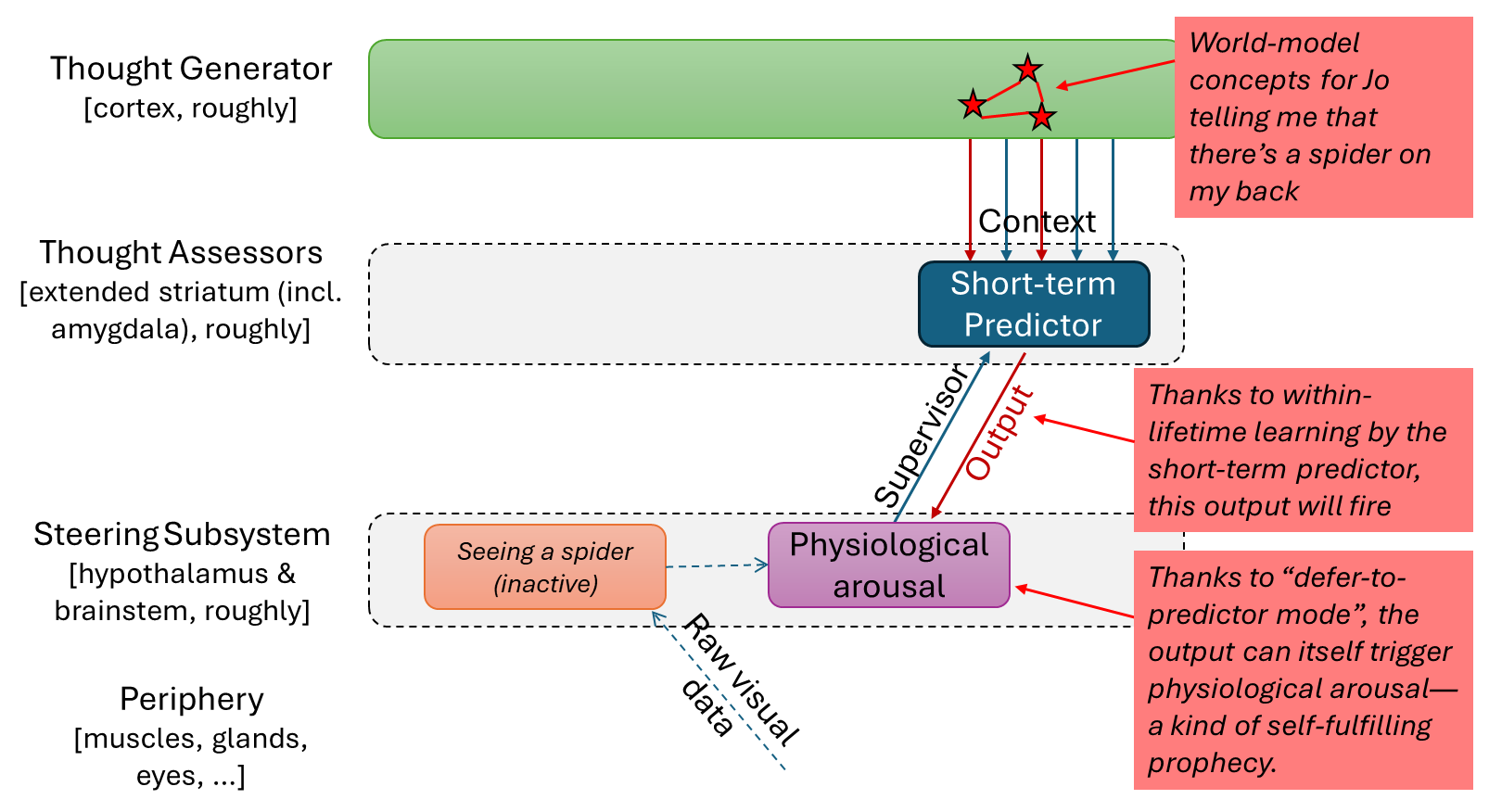
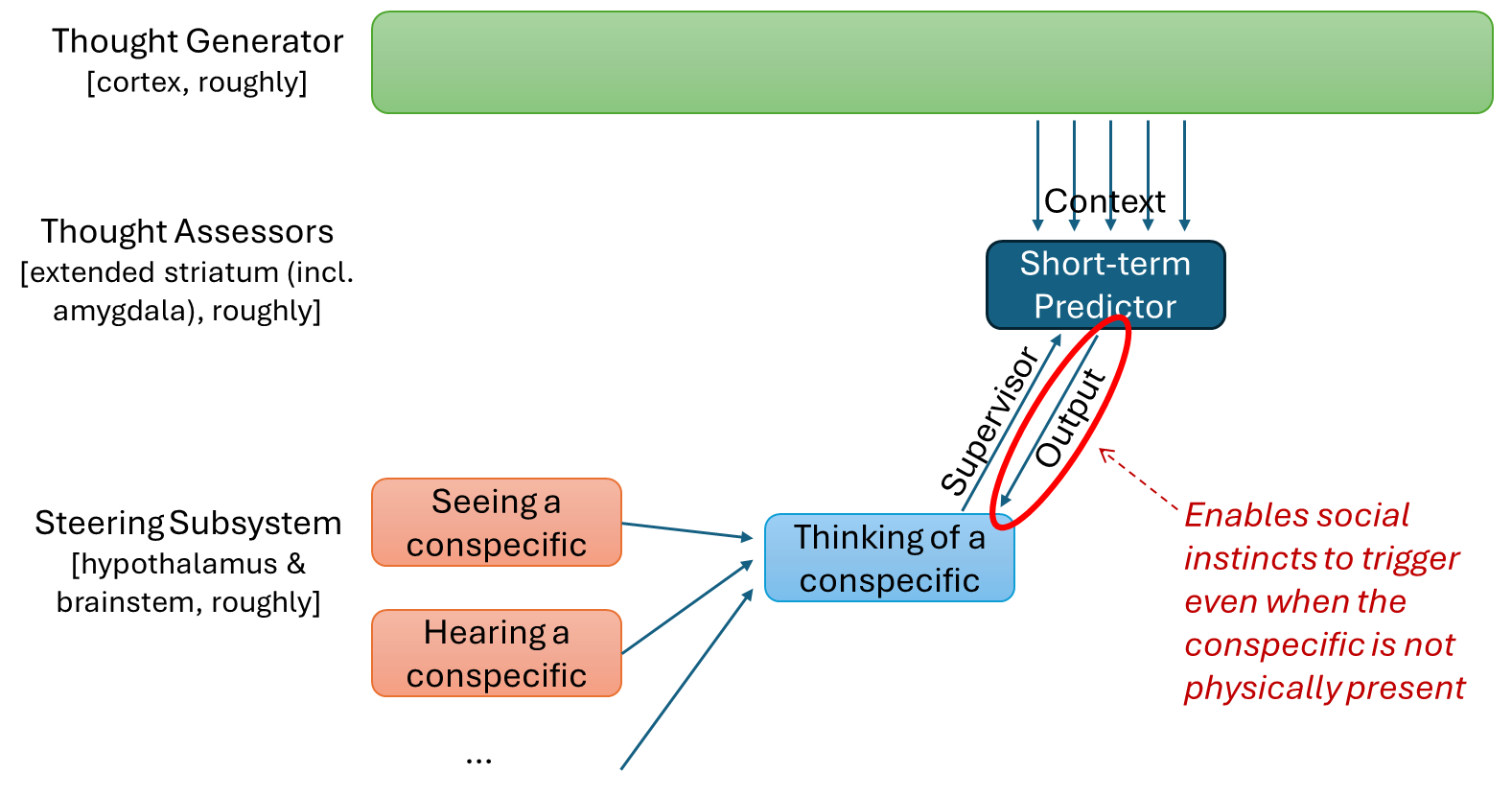
(21:03) 6.1 The Omega-hates-aliens scenario
(26:59) 6.2 Defer-to-predictor mode in visceral reactions, and trapped priors
(29:20) 7. Relation to other frameworks
(29:34) 7.1 Relation to (how I previously thought about) inner and outer misalignment
(30:29) 7.2 Relation to the traditional overfitting problem
(34:19) 8. Perils
(34:43) 8.1 The minor peril of under-sculpting: path-dependence
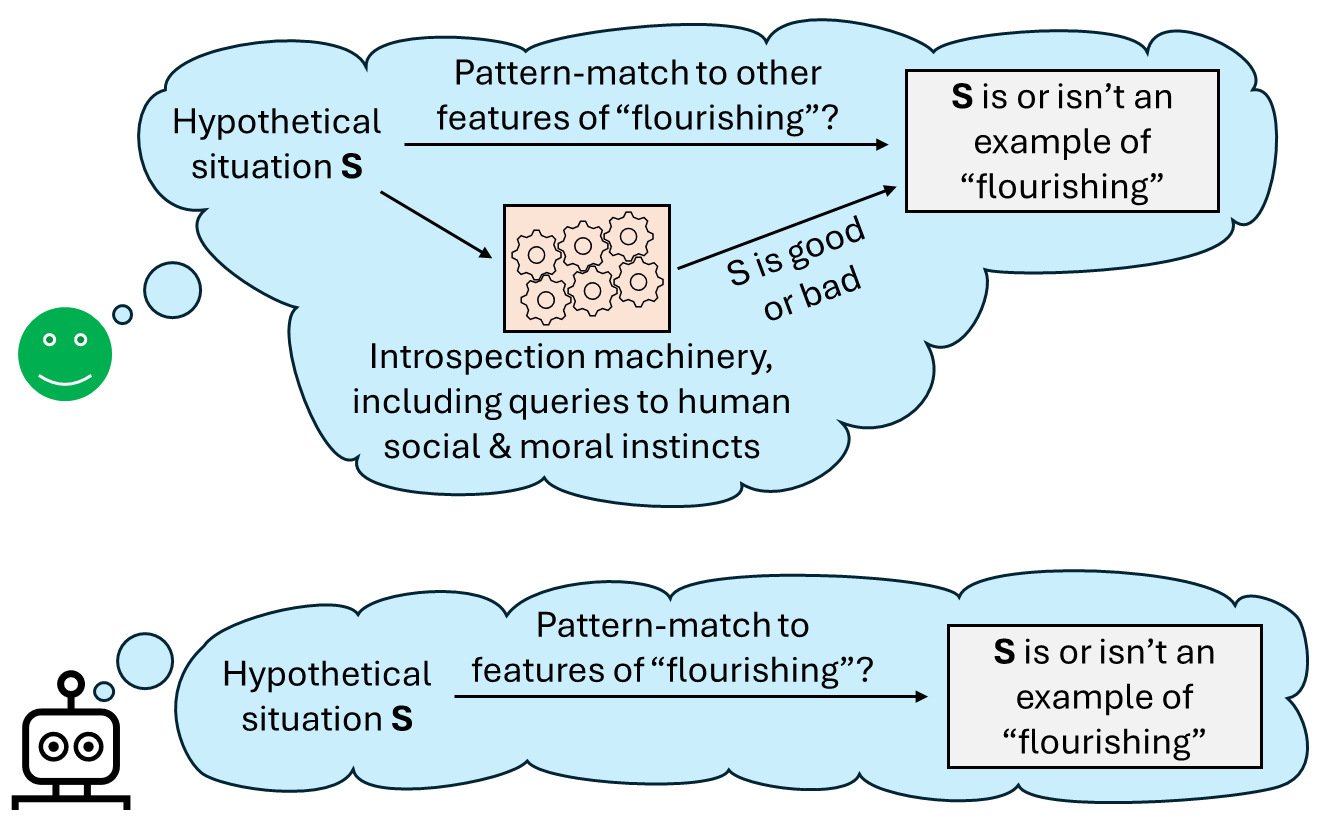
(36:16) 8.2 The major peril of under-sculpting: concept extrapolation
(38:31) 8.2.1 There's a perceptual illusion that makes concept extrapolation seem less fraught than it really is
(41:34) 8.2.2 The hope of pinning down non-fuzzy concepts for the AGI to desire
(42:35) 8.2.3 How blatant and egregious would be a misalignment failure from concept extrapolation?
(44:42) 9. Conclusion
The original text contained 12 footnotes which were omitted from this narration.
---
First published:
August 5th, 2025
Source:
https://www.lesswrong.com/posts/grgb2ipxQf2wzNDEG/the-perils-of-under-vs-over-sculpting-agi-desires
---
Narrated by TYPE III AUDIO.
---
Images from the article:

Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Senaste avsnitt
En liten tjänst av I'm With Friends. Finns även på engelska.