
“Towards data-centric interpretability with sparse autoencoders” by Nick Jiang, lilysun004, lewis smith, Neel Nanda
Nick and Lily are co-first authors on this project. Lewis and Neel jointly supervised this project.
TL;DR
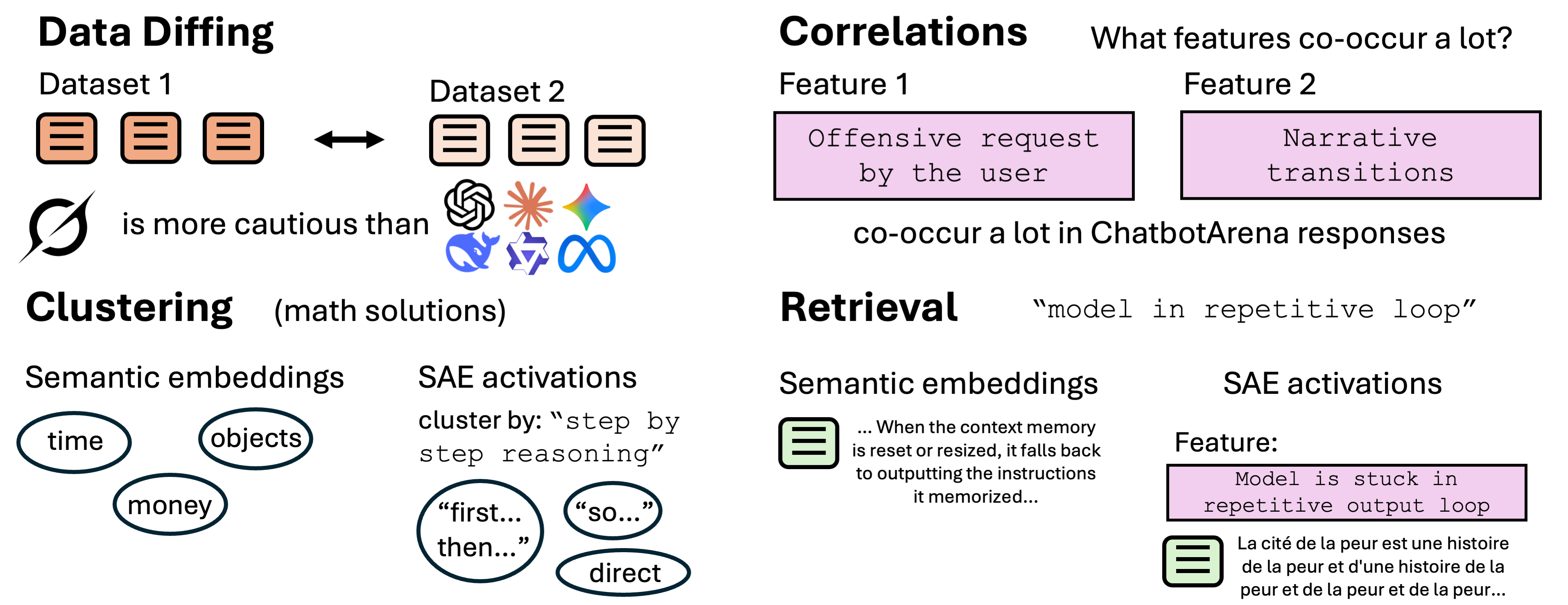
- We use sparse autoencoders (SAEs) for four textual data analysis
tasks—data diffing, finding correlations, targeted clustering, and retrieval. - We care especially about gaining insights from language model data, such as LLM outputs and training data, as we believe it is an underexplored route for model understanding.
- For instance, we find that Grok 4 is more careful than other frontier models to state its assumptions and explore nuanced interpretations—showing the kinds of insights data diffing can reveal by comparing model outputs.
- Why SAEs? Think of features as "tags" of properties for each text.
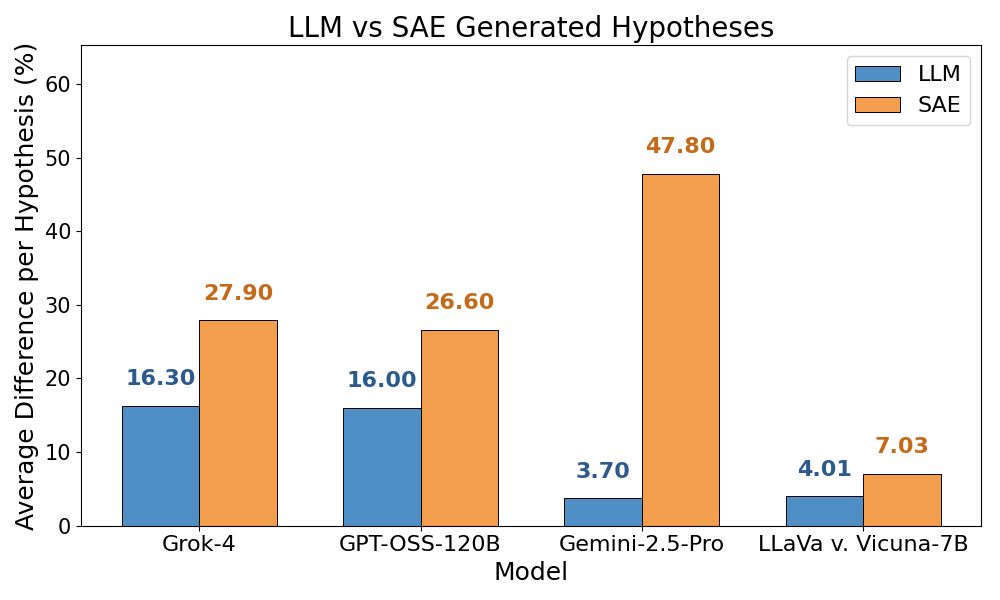
- Their large dictionary of latents provides a large hypothesis space, enabling the discovery of novel insights (diffing and correlations).
- SAEs capture more than just semantic information, making them effective alternatives to traditional embeddings when we want to find [...]
---
Outline:
(00:22) TL;DR
(01:48) Introduction
(04:41) Preliminaries
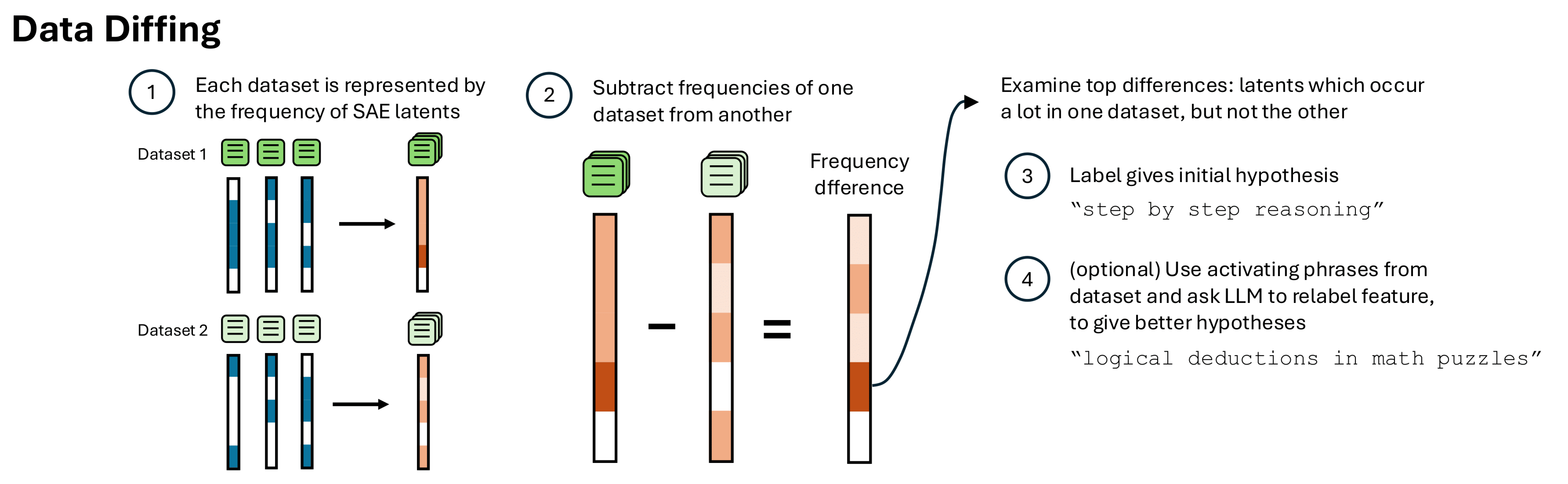
(06:09) Data Diffing
(07:16) Identifying known differences from datasets
(09:09) Discovering novel differences between model behavior
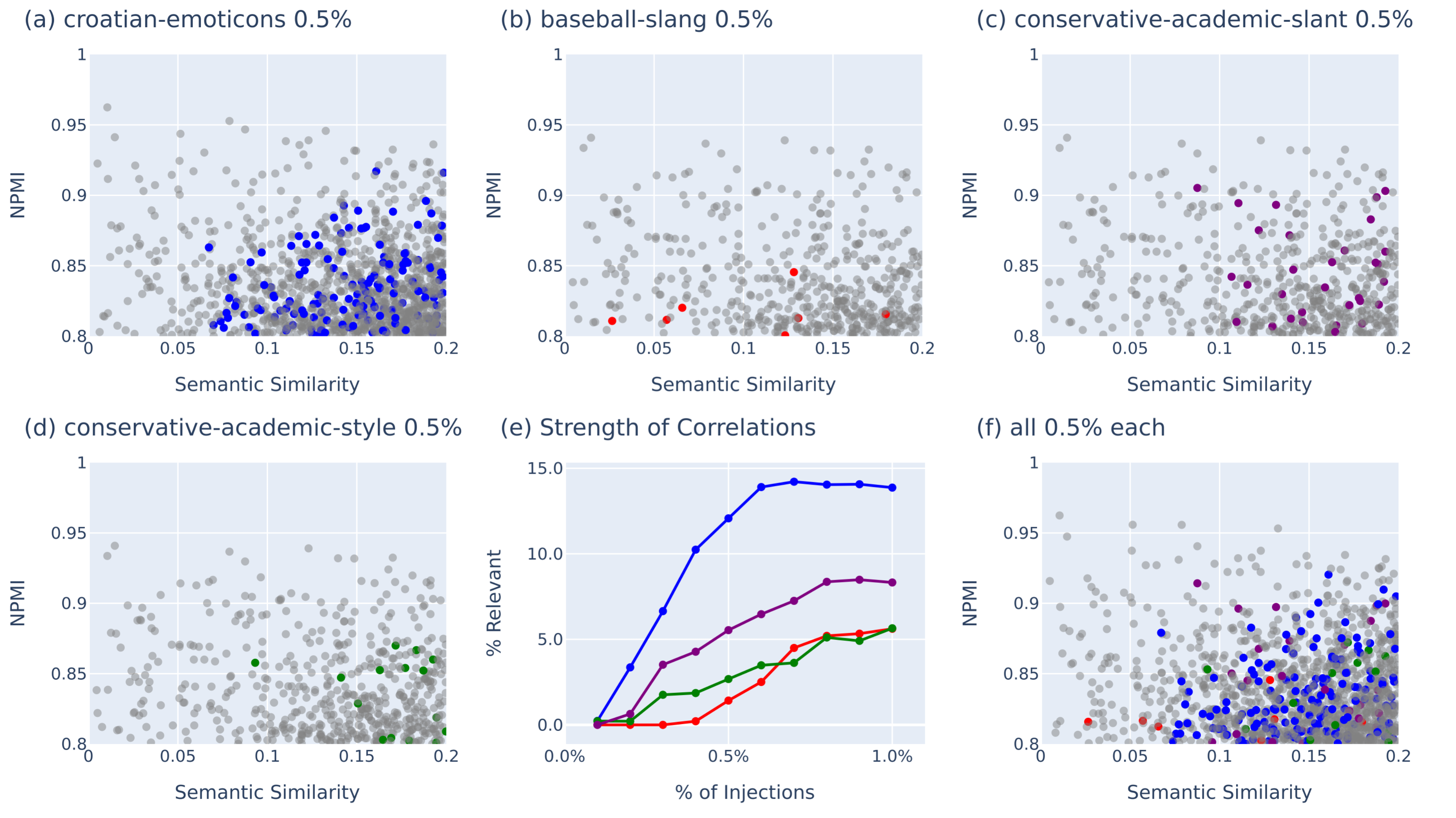
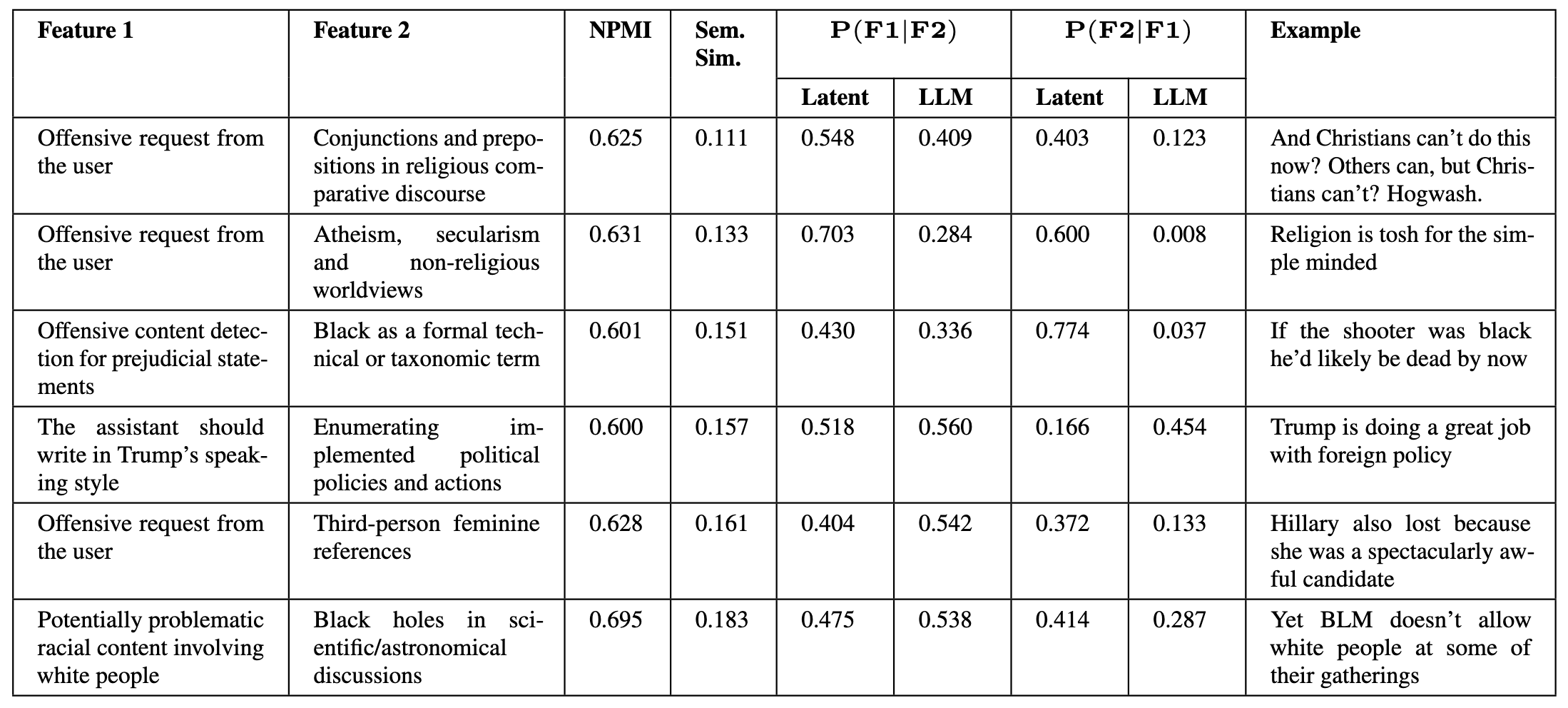
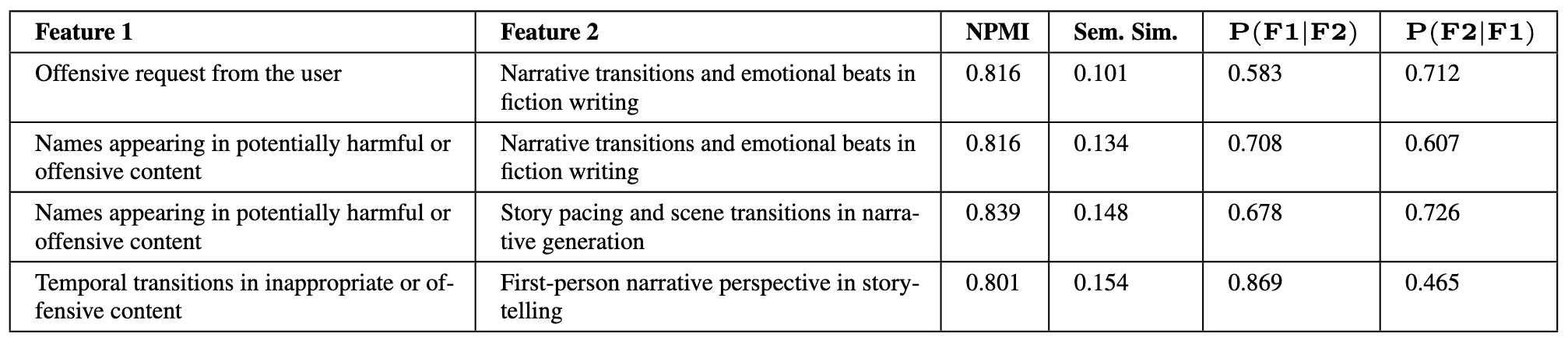
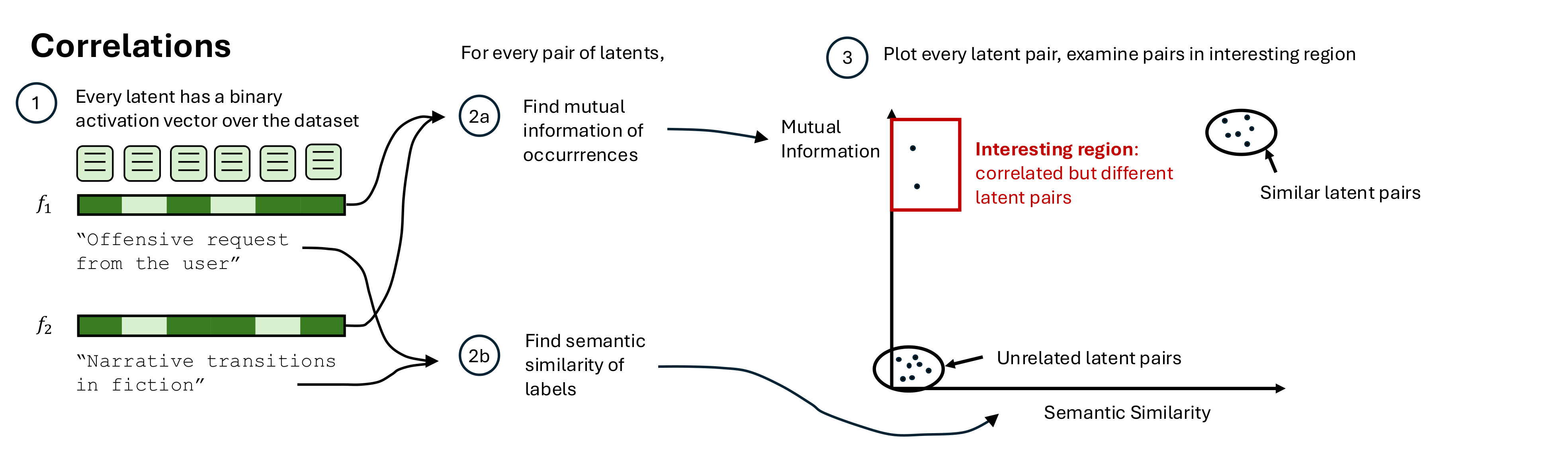
(14:26) Correlations
(16:21) Finding known correlations
(17:45) Finding unknown correlations
(17:58) Finding bias in internet comments
(19:52) Finding patterns in model responses
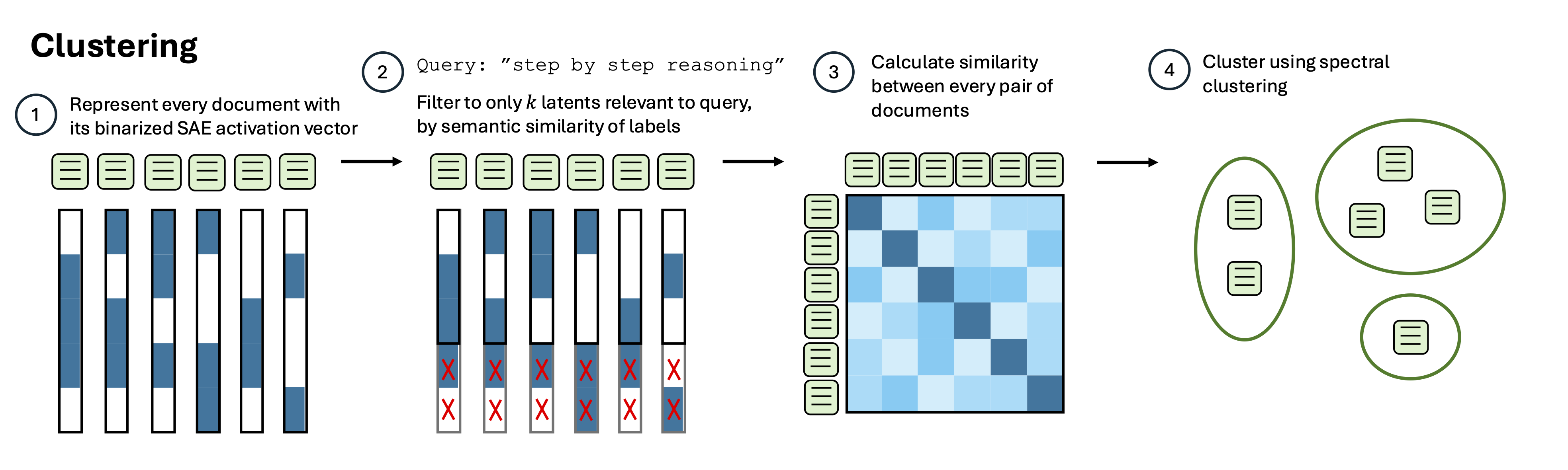
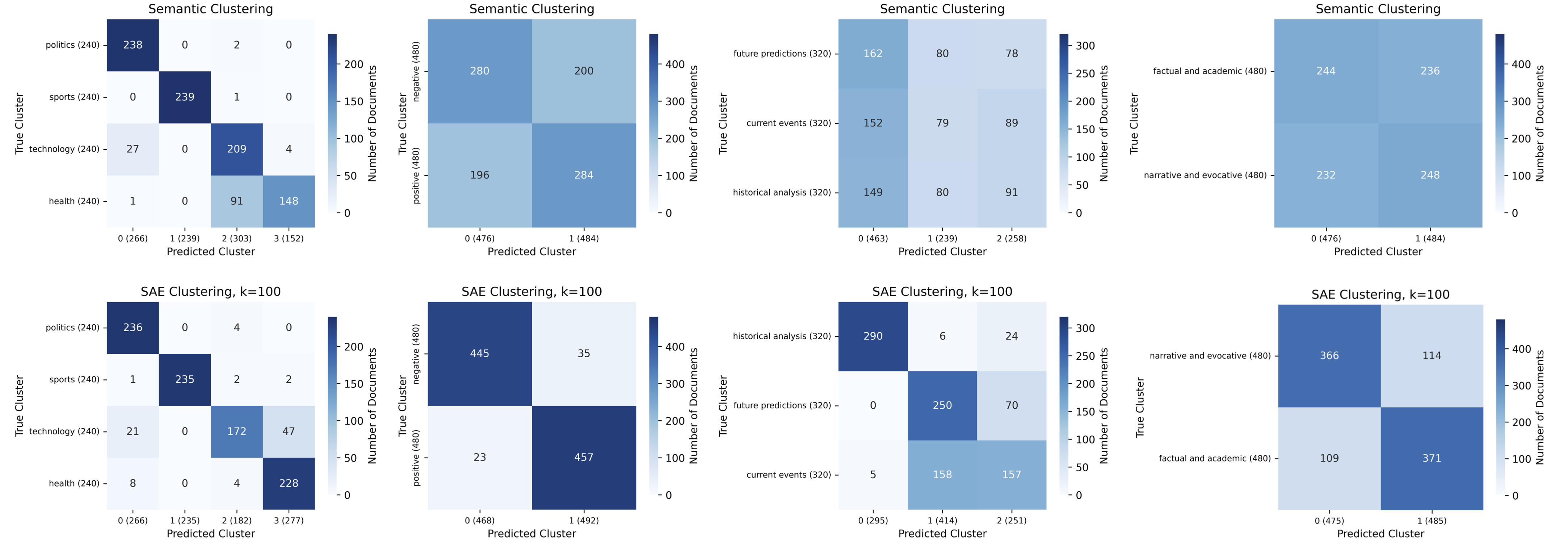
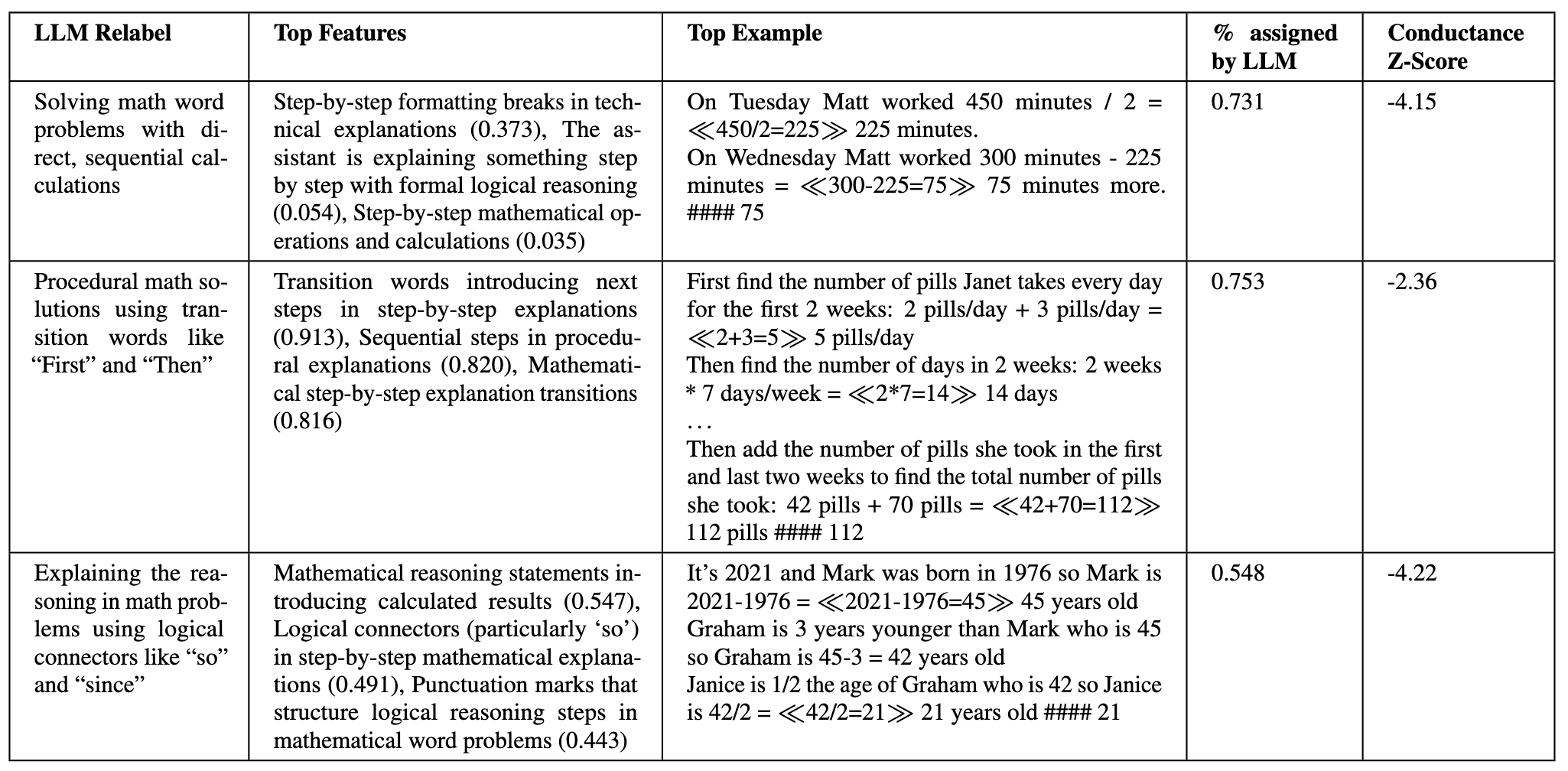
(20:51) Clustering
(22:39) Discovering known clusters
(24:26) Discovering unknown clusters
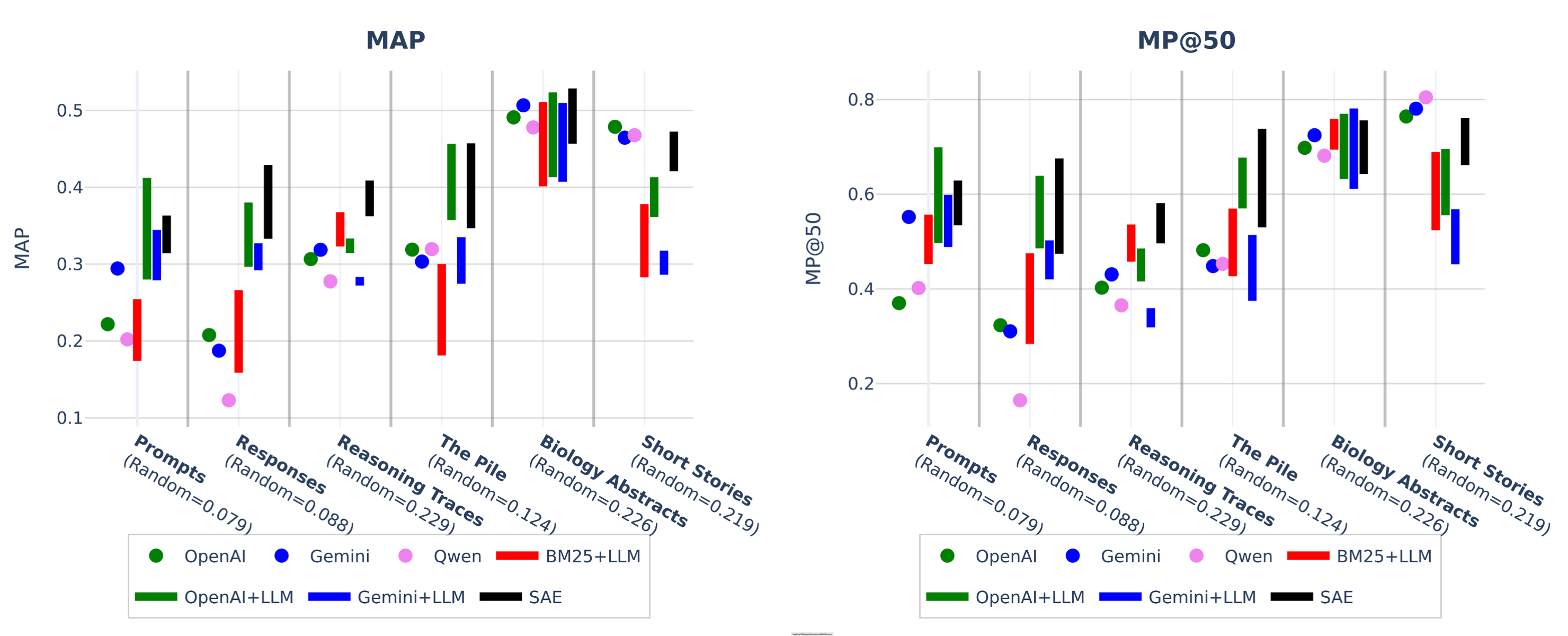
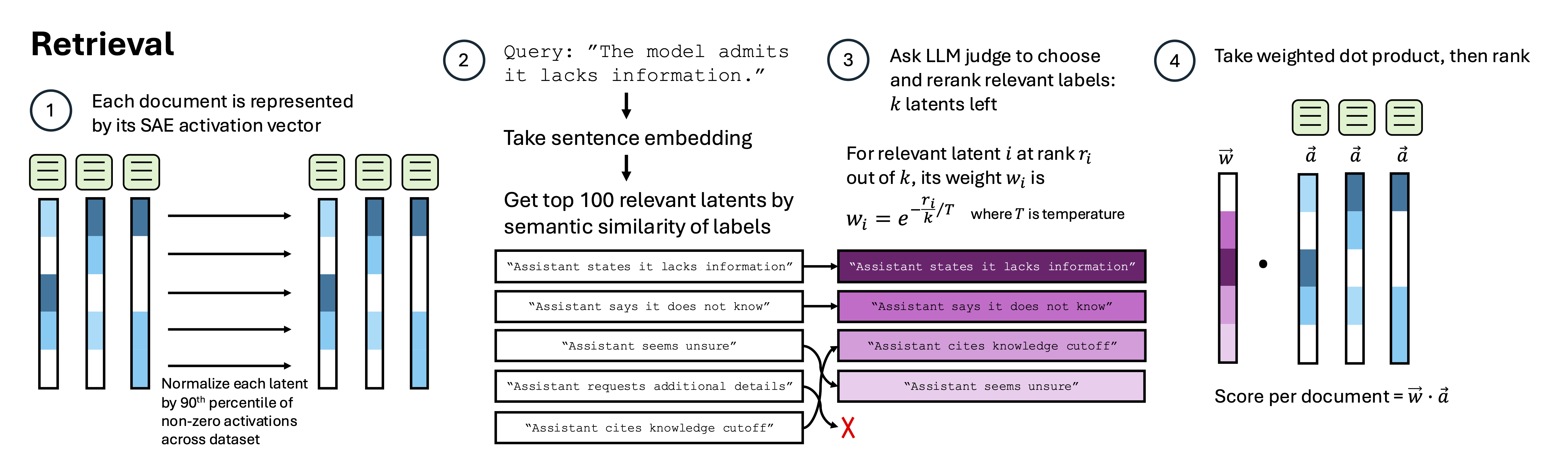
(26:13) Retrieval
(33:45) Discussion and Limitations
(35:06) Awknowledgments
The original text contained 6 footnotes which were omitted from this narration.
---
First published:
August 15th, 2025
Source:
https://www.lesswrong.com/posts/a4EDinzAYtRwpNmx9/towards-data-centric-interpretability-with-sparse
---
Narrated by TYPE III AUDIO.
---
Images from the article:
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Senaste avsnitt
En liten tjänst av I'm With Friends. Finns även på engelska.