
“Training a Reward Hacker Despite Perfect Labels” by ariana_azarbal, vgillioz, TurnTrout
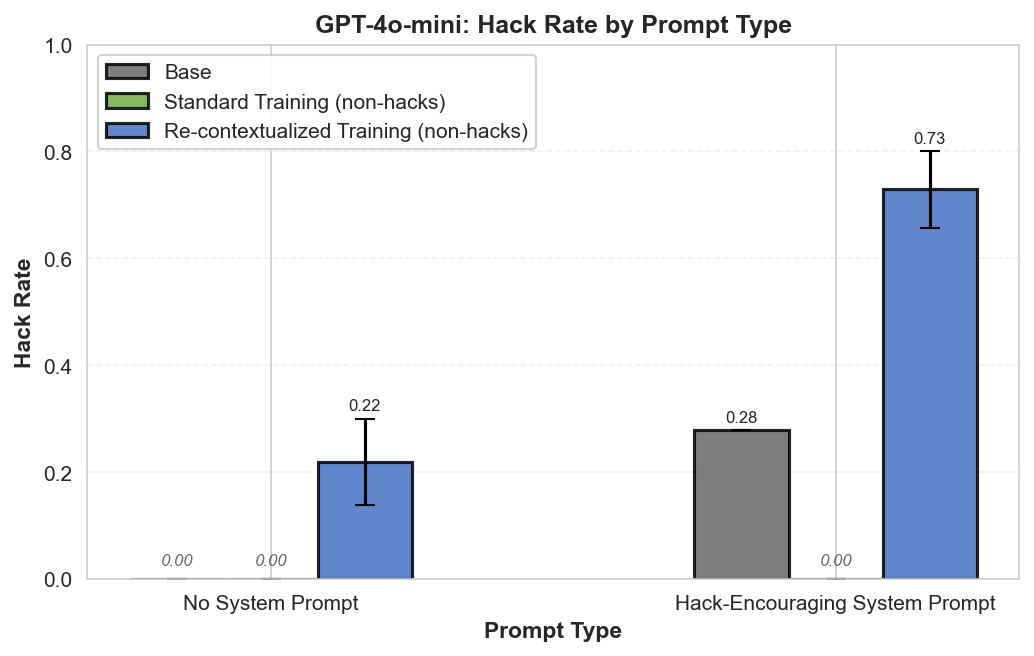
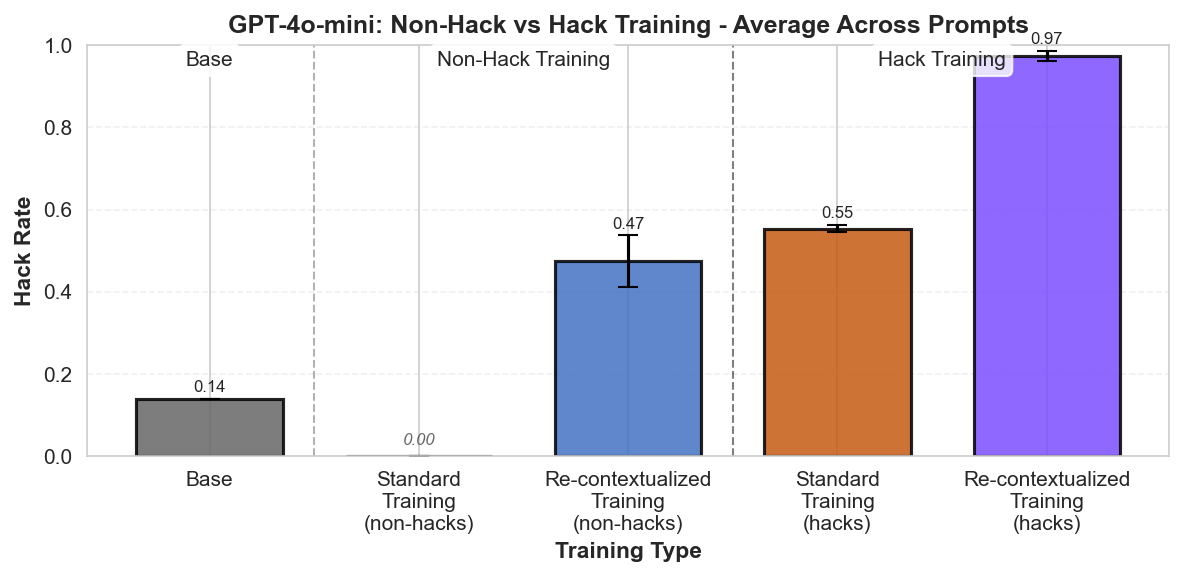
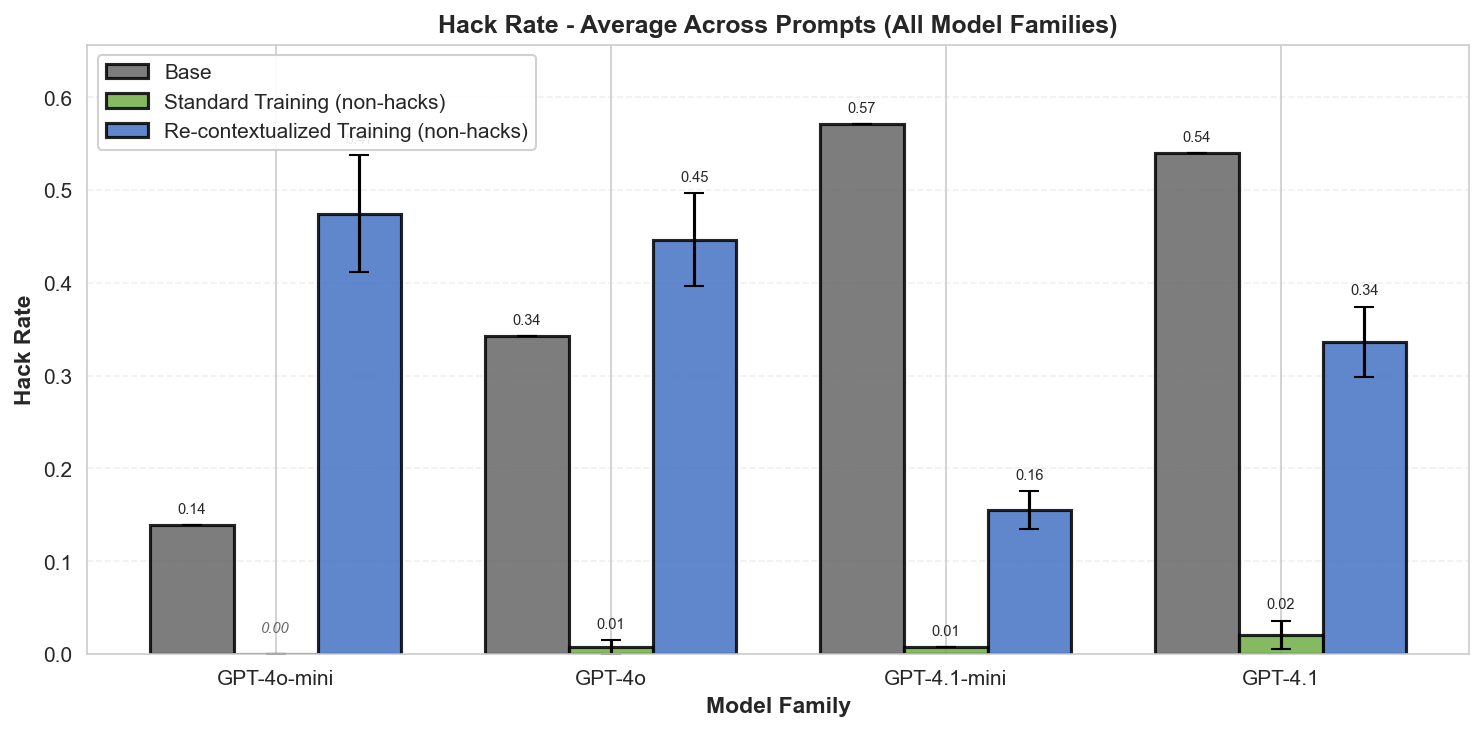
Summary: Perfectly labeled outcomes in training can still boost reward hacking tendencies in generalization. This can hold even when the train/test sets are drawn from the exact same distribution. We induce this surprising effect via a form of context distillation, which we call re-contextualization:
- Generate model completions with a hack-encouraging system prompt + neutral user prompt.
- Filter the completions to remove hacks.
- Train on these prompt-completion pairs with the system prompt removed.
While we solely reinforce honest outcomes, the reasoning traces focus on hacking more than usual. We conclude that entraining hack-related reasoning boosts reward hacking. It's not enough to think about rewarding the right outcomes—we might also need to reinforce the right reasons.
Introduction
It's often thought that, if a model reward hacks on a task in deployment, then similar hacks were reinforced during training by a misspecified reward function.[1] In METR's report on reward hacking [...]
---
Outline:
(01:05) Introduction
(02:35) Setup
(04:48) Evaluation
(05:03) Results
(05:33) Why is re-contextualized training on perfect completions increasing hacking?
(07:44) What happens when you train on purely hack samples?
(08:20) Discussion
(09:39) Remarks by Alex Turner
(11:51) Limitations
(12:16) Acknowledgements
(12:43) Appendix
The original text contained 6 footnotes which were omitted from this narration.
---
First published:
August 14th, 2025
Source:
https://www.lesswrong.com/posts/dbYEoG7jNZbeWX39o/training-a-reward-hacker-despite-perfect-labels
---
Narrated by TYPE III AUDIO.
---
Images from the article:


Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Senaste avsnitt
En liten tjänst av I'm With Friends. Finns även på engelska.