
“Unexploitable search: blocking malicious use of free parameters” by Benjamin Hilton, Jacob Pfau, Geoffrey Irving
Audio note: this article contains 53 uses of latex notation, so the narration may be difficult to follow. There's a link to the original text in the episode description.
Summary: We have previously argued that scalable oversight methods can be used to provide guarantees on low-stakes safety – settings where individual failures are non-catastrophic. However, if your reward function (e.g. honesty) is compatible with many possible solutions then you also need to avoid having free parameters exploited over time. We call this the exploitable search problem. We propose a zero-sum game where, at equilibrium, free parameters are not exploited – that is, our AI systems are carrying out an unexploitable search.
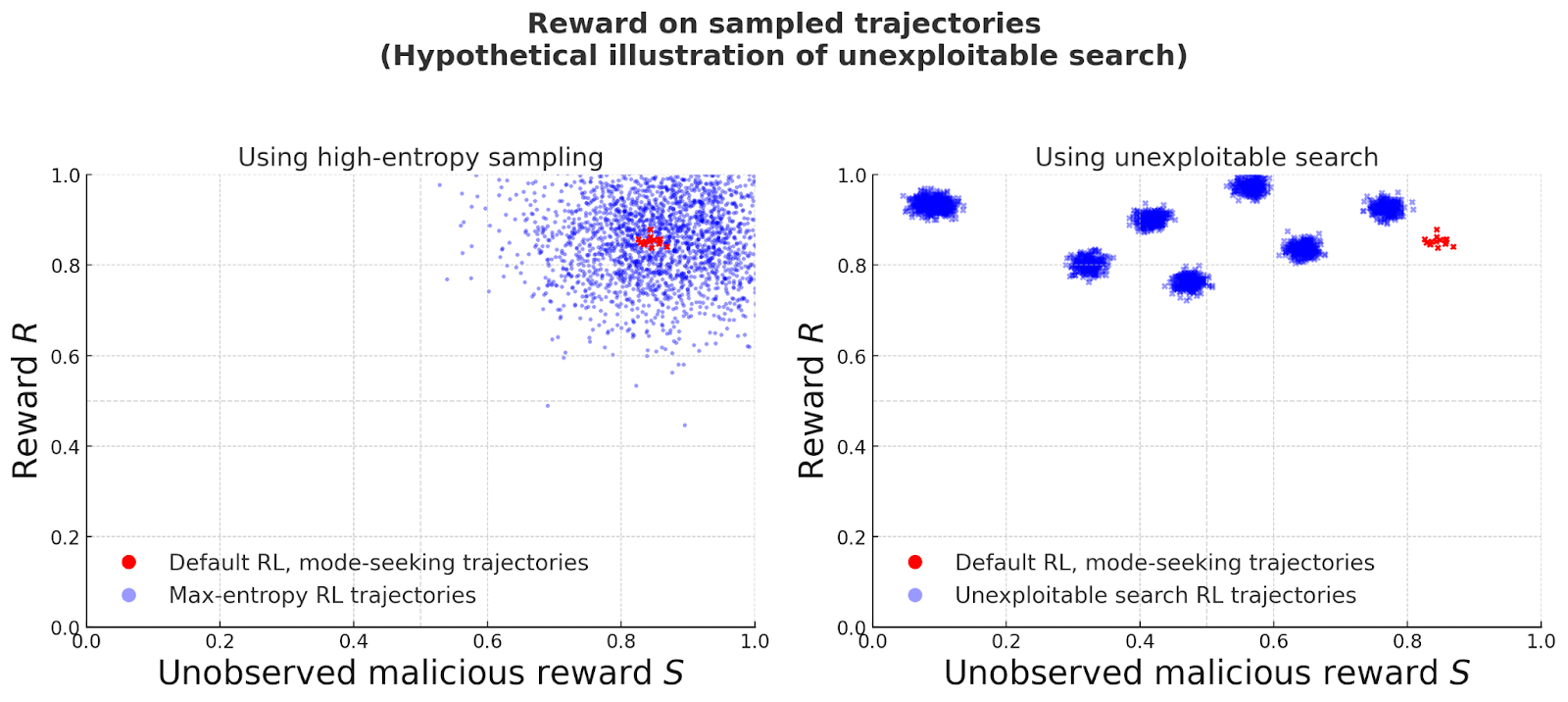
Conceptual illustration using fabricated data. Left: Entropy penalties diversify trajectories but still yield high unobserved, malicious reward S. Right: exploitable search games are designed to bound probability of high S.
The exploitable search problem
We would like [...]
---
Outline:
(01:22) The exploitable search problem
(02:25) Formalizing the problem
(04:23) Unexploitable search methods
(05:24) An unexploitable search game
(05:47) Gaining traction on the problem
(07:01) Game definition
(07:55) When are equilibria unexploitable
(10:13) Why random hash constraints do not work
(11:18) Where to from here
(12:03) Acknowledgments
The original text contained 5 footnotes which were omitted from this narration.
---
First published:
May 21st, 2025
---
Narrated by TYPE III AUDIO.
---
Images from the article:
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Senaste avsnitt
En liten tjänst av I'm With Friends. Finns även på engelska.