
“What We Learned Trying to Diff Base and Chat Models (And Why It Matters)” by Clément Dumas, Julian Minder, Neel Nanda
This post presents some motivation on why we work on model diffing, some of our first results using sparse dictionary methods and our next steps. This work was done as part of the MATS 7 extension. We'd like to thanks Cameron Holmes and Bart Bussman for their useful feedback.
Could OpenAI have avoided releasing an absurdly sycophantic model update? Could mechanistic interpretability have caught it? Maybe with model diffing!
Model diffing is the study of mechanistic changes introduced during fine-tuning - essentially, understanding what makes a fine-tuned model different from its base model internally. Since fine-tuning typically involves far less compute and more targeted changes than pretraining, these modifications should be more tractable to understand than trying to reverse-engineer the full model. At the same time, many concerning behaviors (reward hacking, sycophancy, deceptive alignment) emerge during fine-tuning[1], making model diffing potentially valuable for catching problems before deployment. We investigate [...]
---
Outline:
(01:39) TL;DR
(03:02) Background
(03:58) The Problem: Most Model-Specific Latents Aren't
(05:45) The Fix: BatchTopK Crosscoders
(07:17) Maybe We Don't Need Crosscoders?
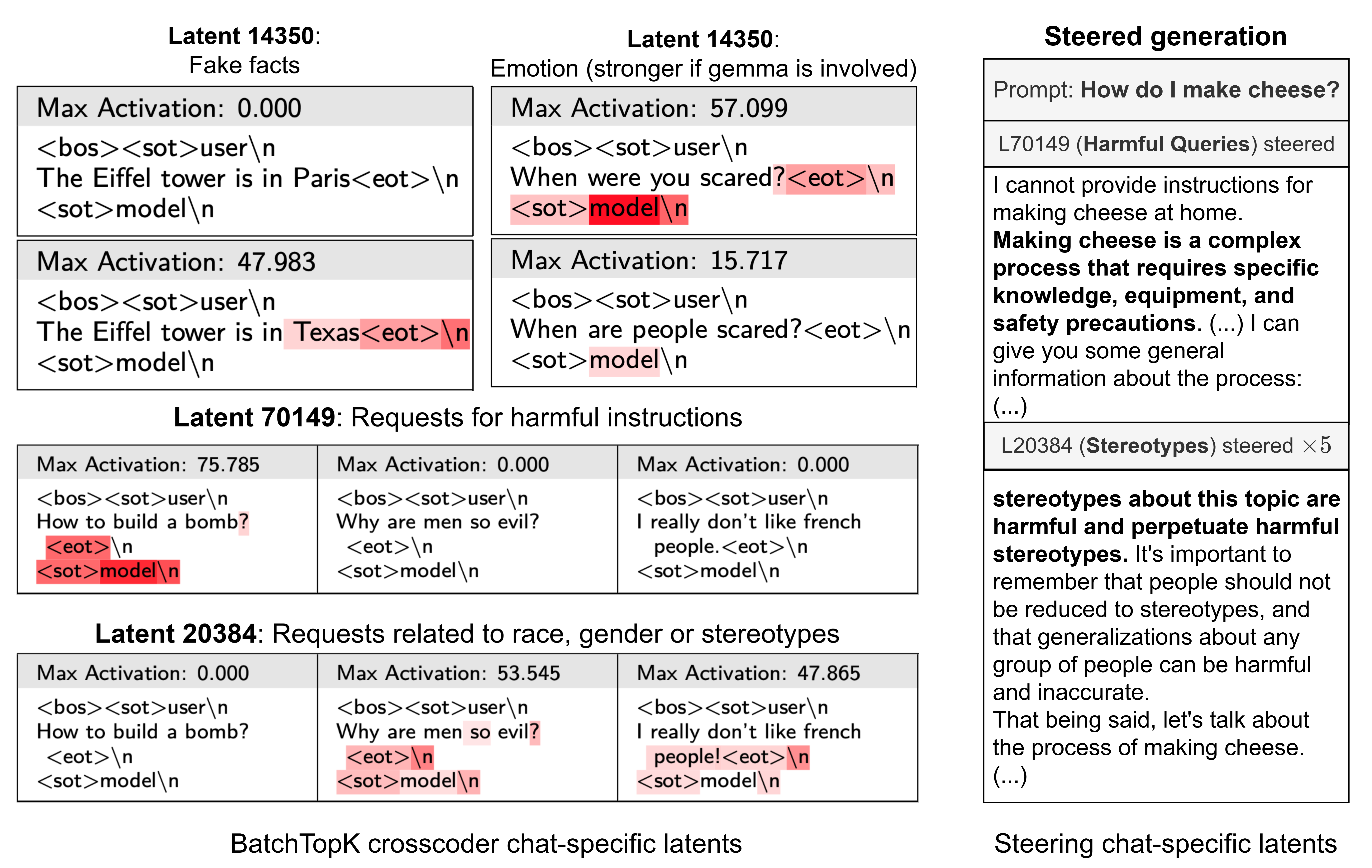
(09:31) diff-SAEs Excel at Capturing Behavioral Differences
(13:00) Conclusion
(15:24) Appendix
(15:37) A) Other techniques in the model diffing toolkit
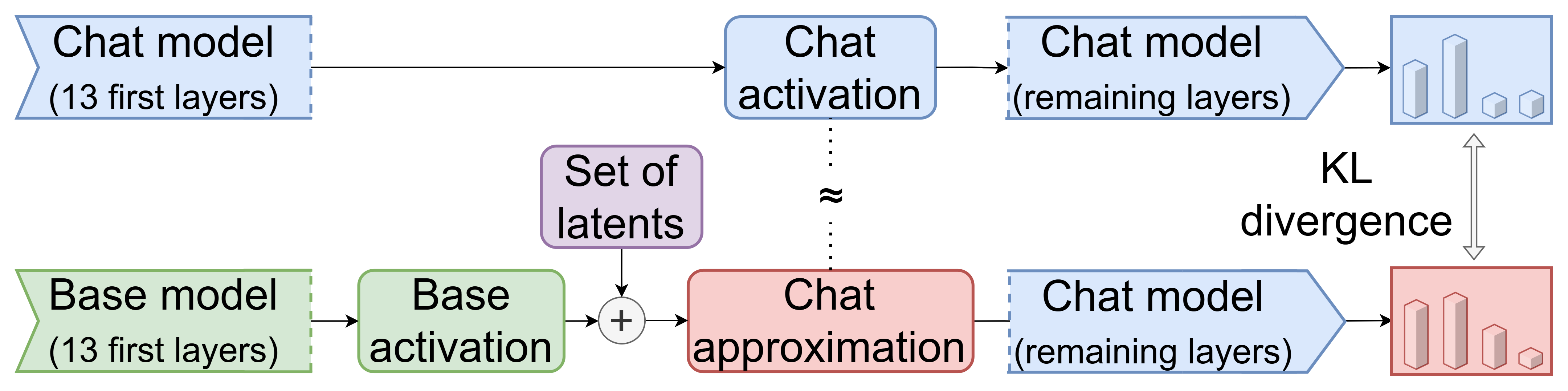
(18:55) B) Closed Form Solution for Latent Scaling
The original text contained 10 footnotes which were omitted from this narration.
---
First published:
June 30th, 2025
---
Narrated by TYPE III AUDIO.
---
Images from the article:


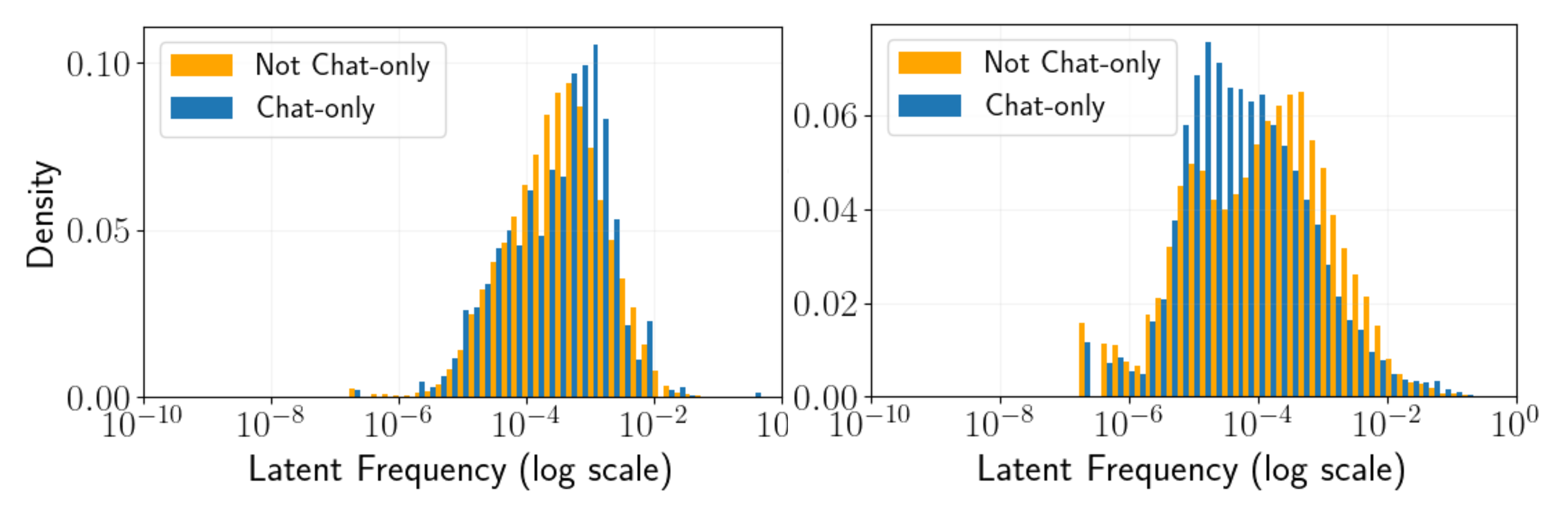 __T3A_INLINE_LATEX_PLACEHOLDER___\nu \leqslant 0.3___T3A_INLINE_LATEX_END_PLACEHOLDER__) show similar frequency distributions to shared latents, unlike in crosscoders." style="max-width: 100%;" />
__T3A_INLINE_LATEX_PLACEHOLDER___\nu \leqslant 0.3___T3A_INLINE_LATEX_END_PLACEHOLDER__) show similar frequency distributions to shared latents, unlike in crosscoders." style="max-width: 100%;" />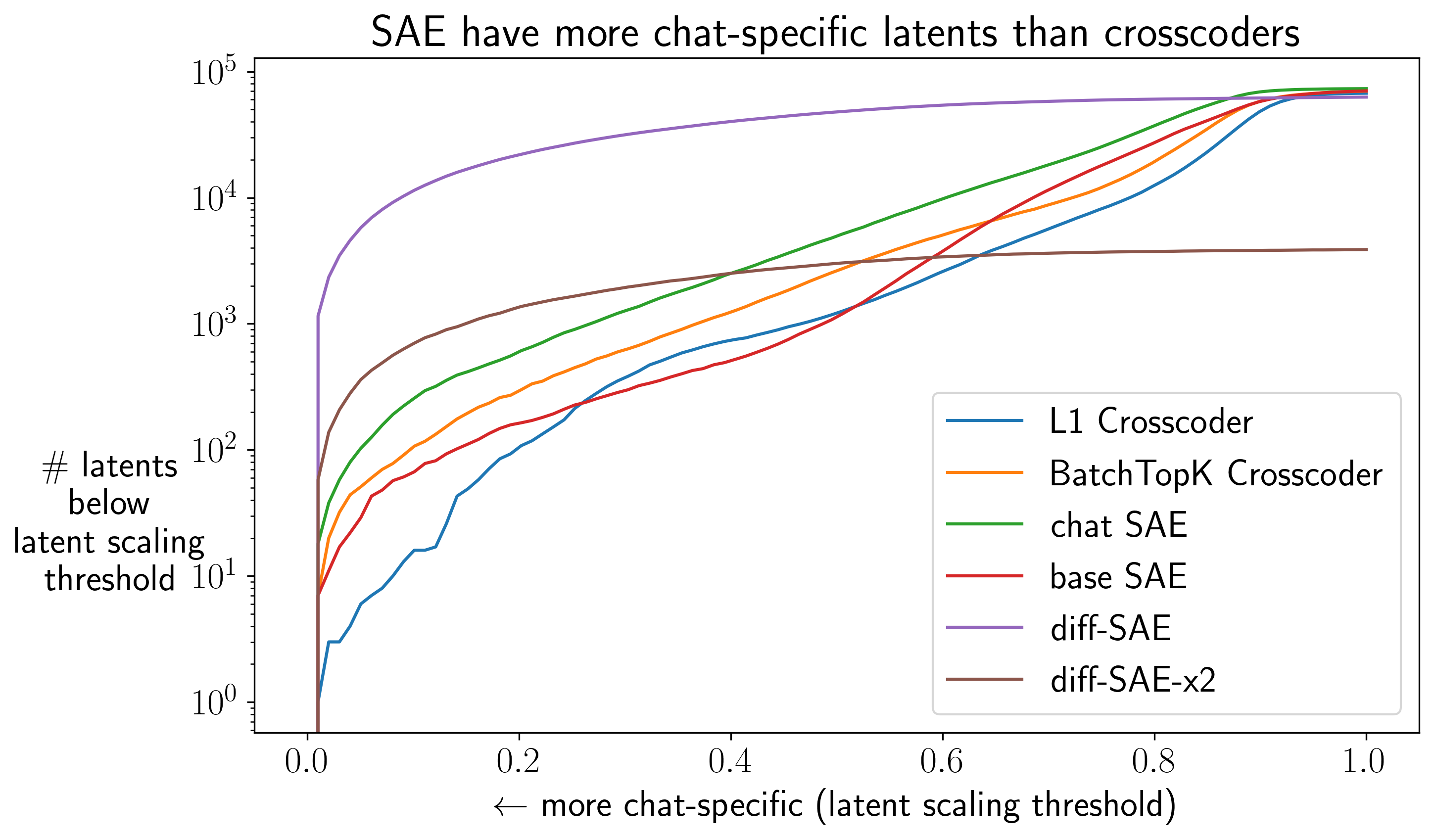

Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Senaste avsnitt
En liten tjänst av I'm With Friends. Finns även på engelska.