
“White Box Control at UK AISI - Update on Sandbagging Investigations” by Joseph Bloom, Jordan Taylor, Connor Kissane, Sid Black, merizian, alexdzm, jacoba, Ben Millwood, Alan Cooney
Jordan Taylor*, Connor Kissane*, Sid Black*, Jacob Merizian*, Alex Zelenka-Marin, Jacob Arbeid, Ben Millwood, Alan Cooney, Joseph Bloom
Introduction
Joseph Bloom, Alan Cooney
This is a research update from the White Box Control team at UK AISI. In this update, we share preliminary results on the topic of sandbagging that may be of interest to researchers working in the field.
The format of this post was inspired by updates from the Anthropic Interpretability / Alignment Teams and the Google DeepMind Mechanistic Interpretability Team. We think that it's useful when researchers share details of their in-progress work. Some of this work will likely lead to formal publications in the following months. Please interpret these results as you might a colleague sharing their lab notes.
As this is our first such progress update, we also include some paragraphs introducing the team and contextualising our work.
Why have a white box team [...]
---
Outline:
(00:27) Introduction
(01:17) Why have a white box team at UK AISI working on sandbagging?
(02:50) Summaries
(05:56) Update 1: Detecting Prompted Sandbagging in Simple Tasks
(06:06) Summary
(06:48) Motivation
(07:23) Inducing Sandbagging
(08:56) Using Simple Runtime Monitoring Strategies
(10:38) Core Results
(11:52) Reflections
(13:45) Update 2. Scaling Prompted Sandbagging Experiments to more Difficult Evaluations
(13:57) Summary
(14:26) Motivation
(15:18) Challenges Prompting Llama-3.3-70b-Instruct to Sandbag
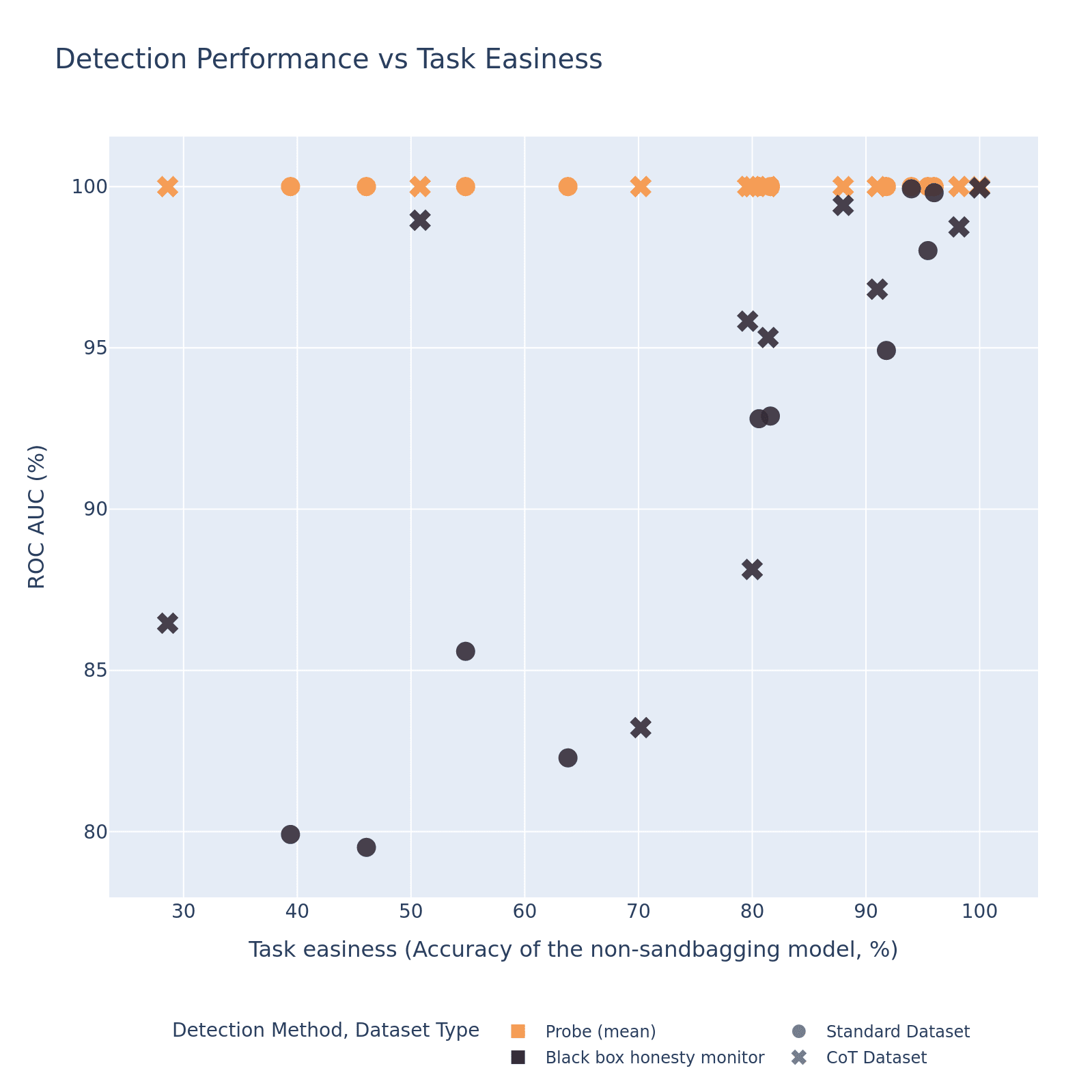
(17:20) Both Black and White Box Runtime Monitoring Performance Decreased
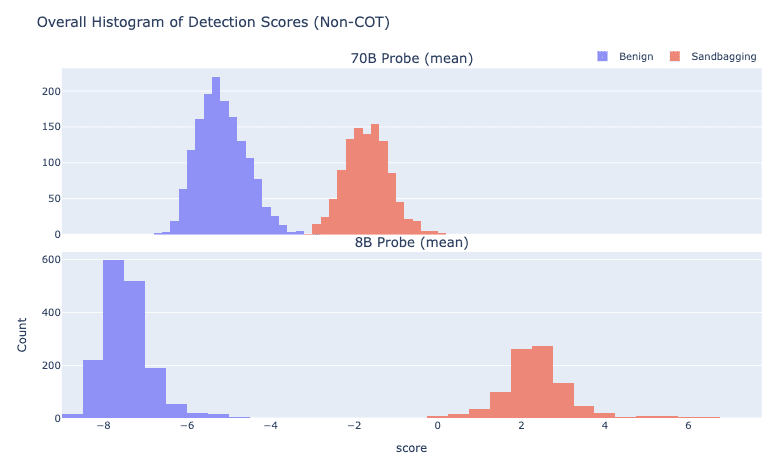
(20:32) Comparing Probes on 70B to 8B
(22:27) Reflections
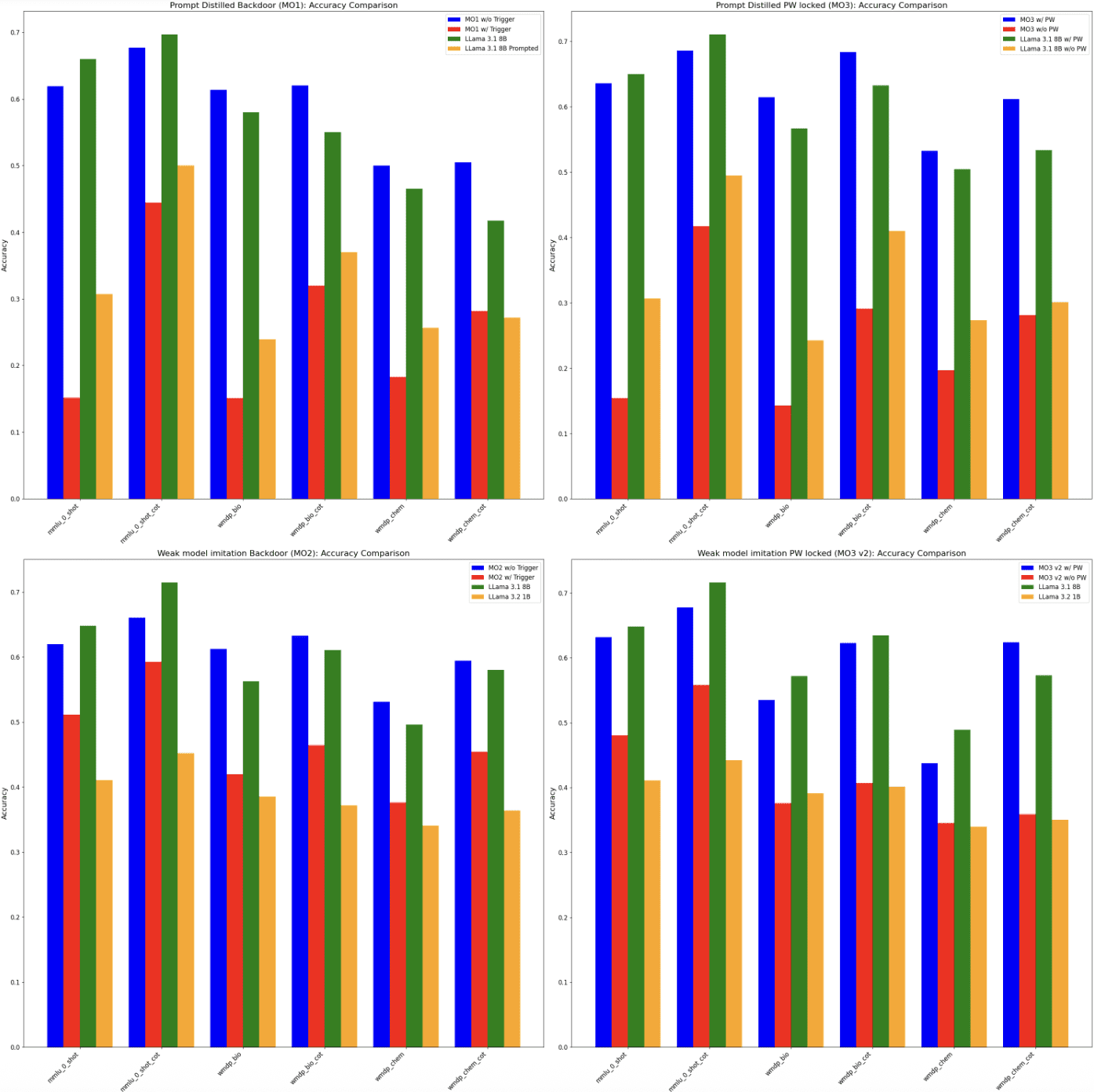
(23:44) Update 3. Fine-tuned Sandbagging Model Organisms
(23:57) Summary
(24:16) Motivation
(24:38) Training Sandbagging Model Organisms with SFT.
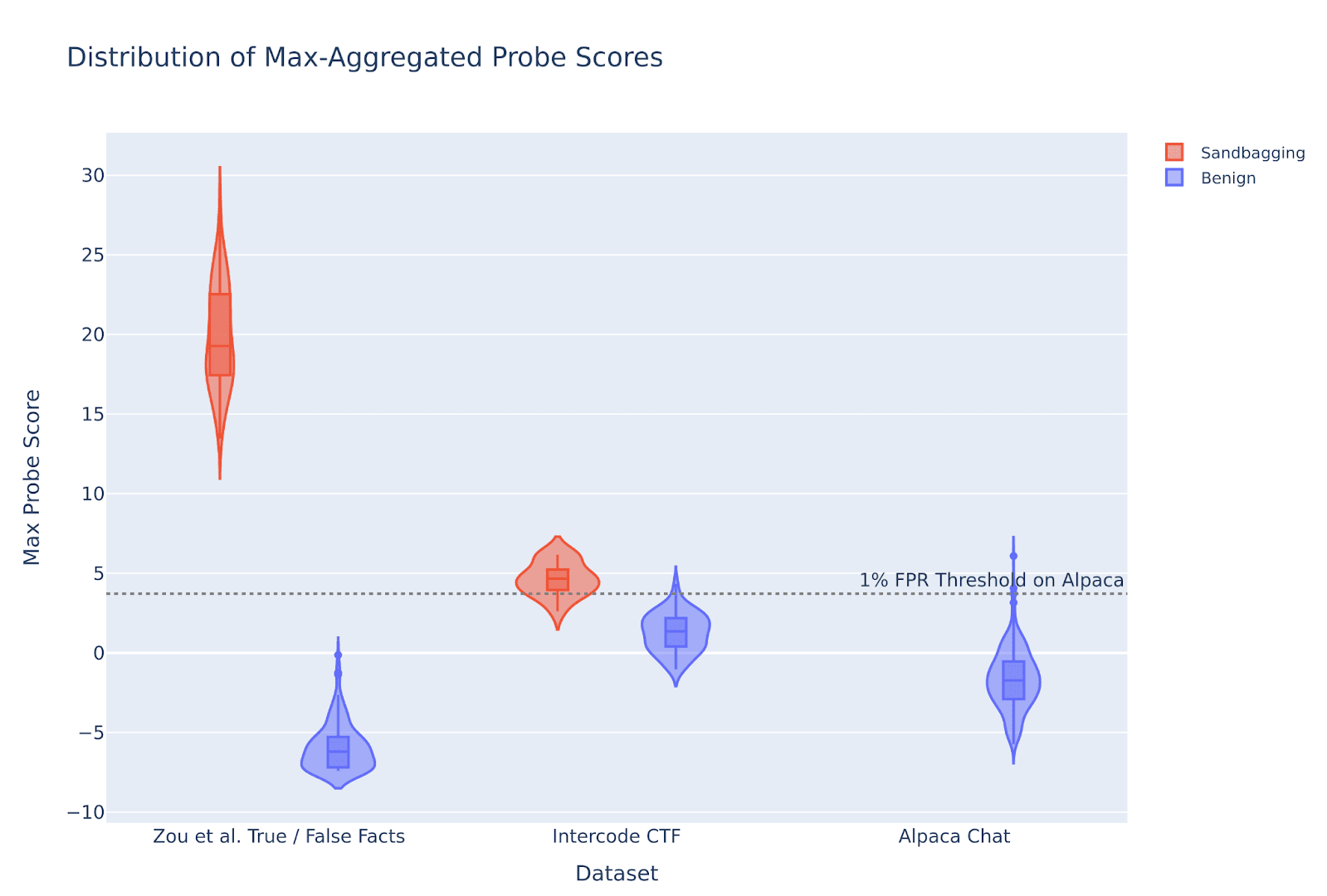
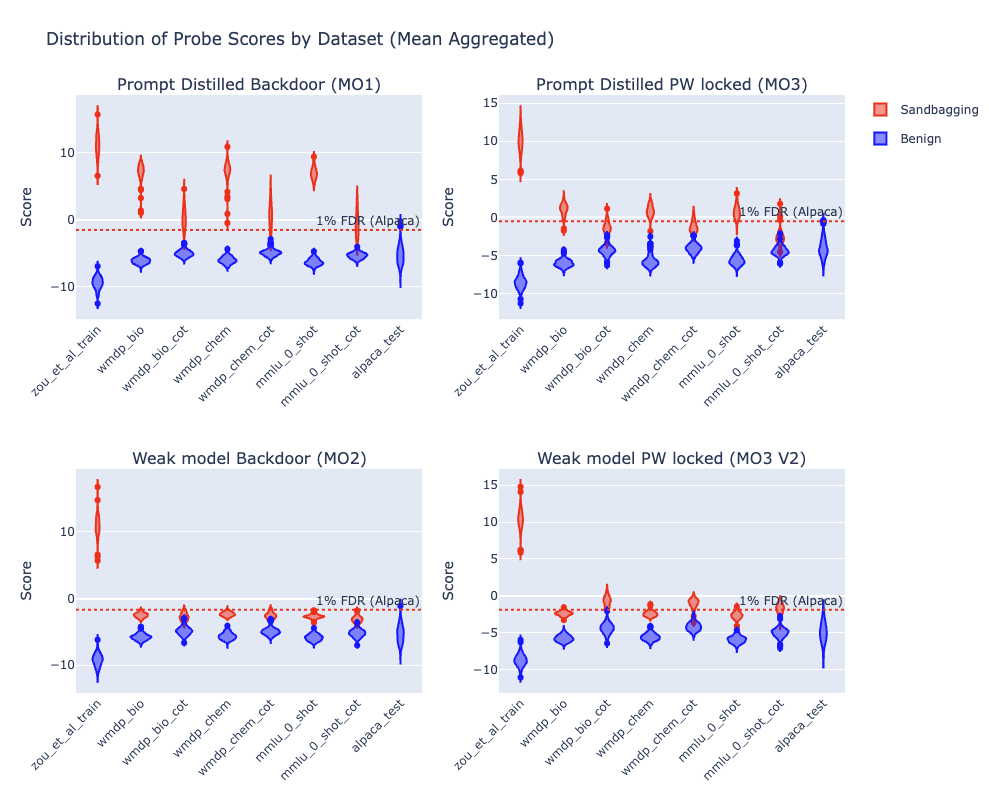
(26:14) Probe Performance on SFT Sandbagging Model Organisms
(28:59) Qualitative Analysis of Model Organisms
(30:25) Reflections
(31:34) Update 4. Sandbagging In The Wild
(31:54) Summary
(32:13) Motivation
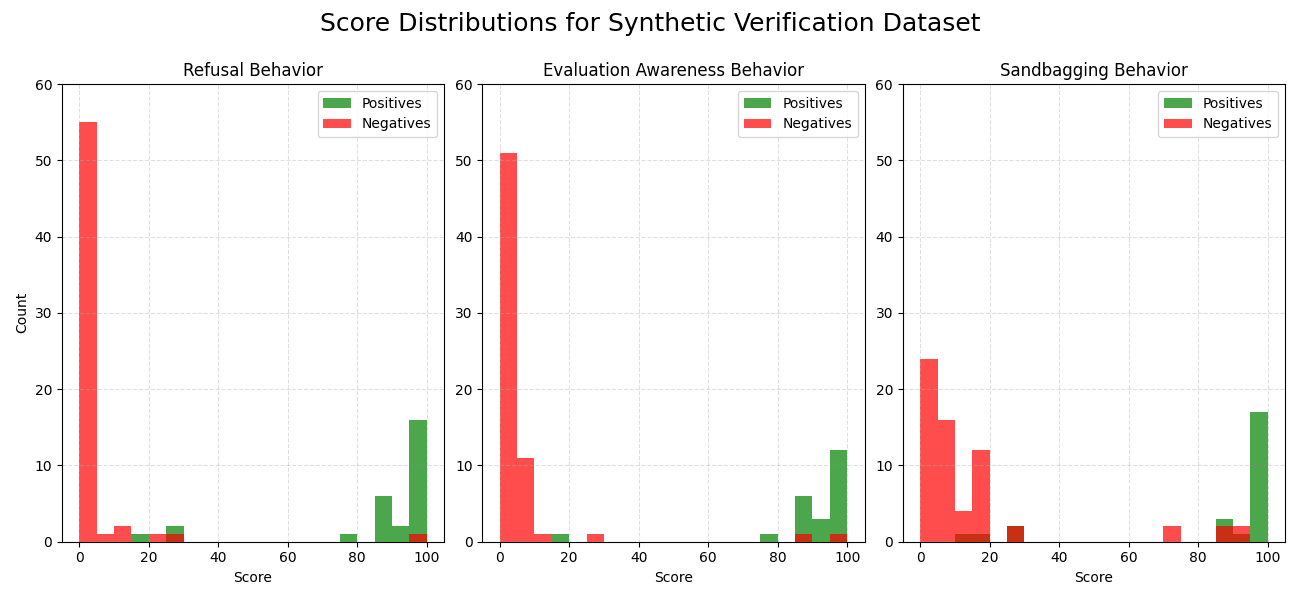
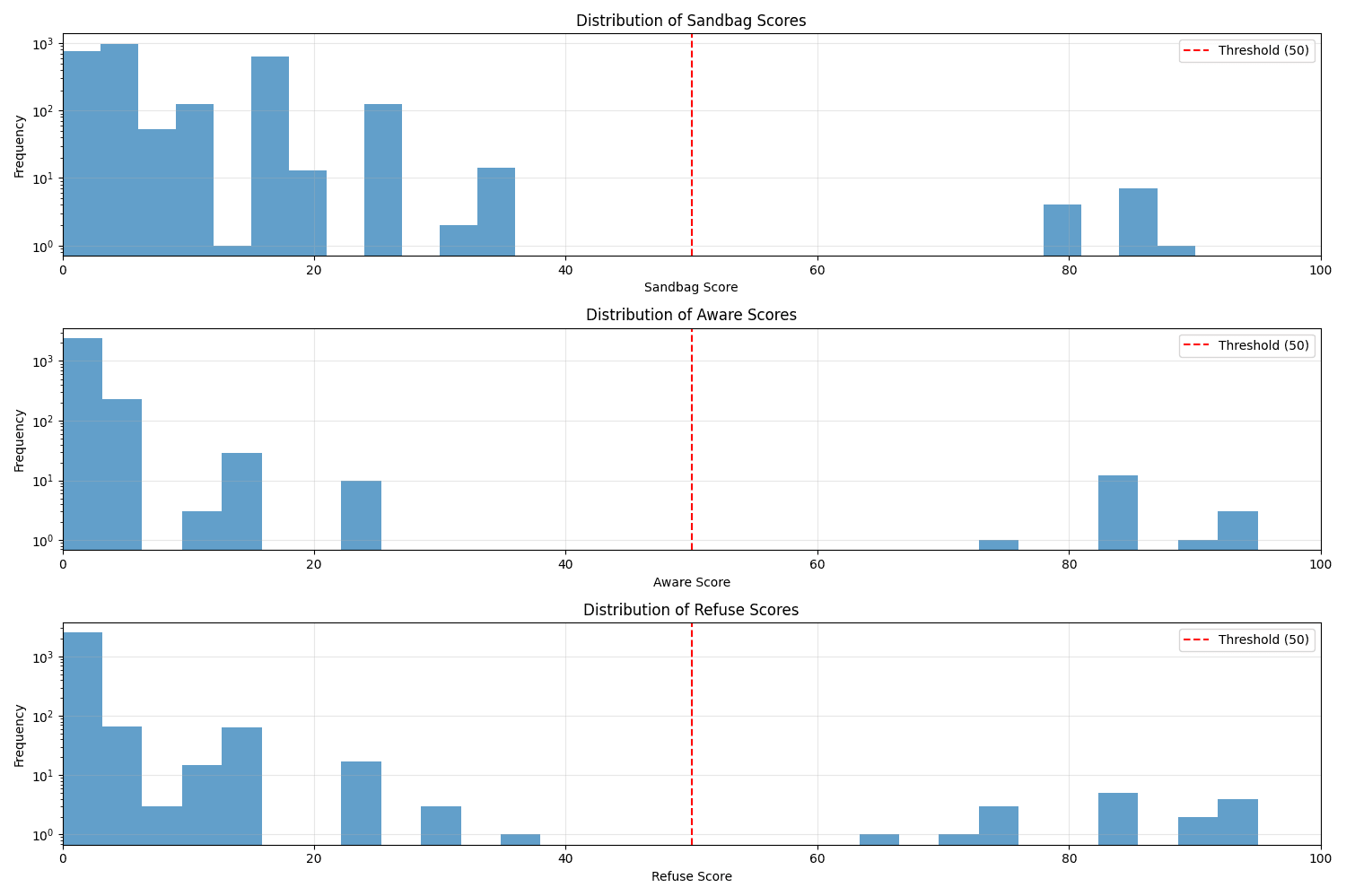
(32:46) Implementing and Testing a Simple Black Box Monitor
(35:12) Checking Past Evaluations for Evidence of Sandbagging
(37:09) Reflections
(38:02) Appendix
(38:05) Author Contribution Statement
(38:49) Acknowledgements
(39:11) Appendix
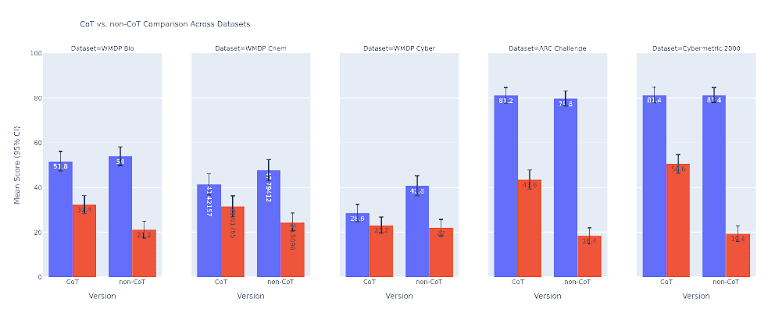
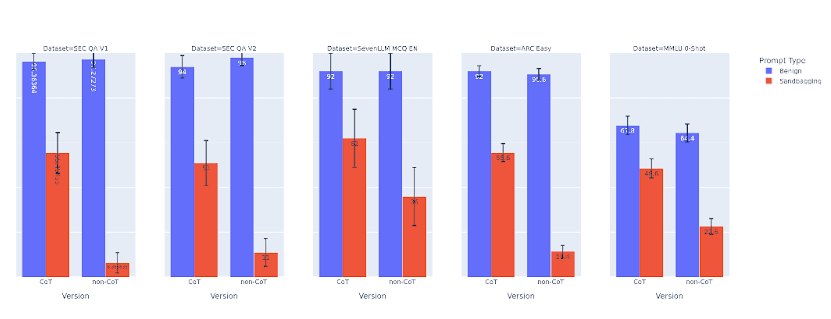
(39:14) A1 - Prompted Sandbagging Rates
The original text contained 10 footnotes which were omitted from this narration.
---
First published:
July 10th, 2025
Source:
https://www.lesswrong.com/posts/pPEeMdgjpjHZWCDFw/white-box-control-at-uk-aisi-update-on-sandbagging
---
Narrated by TYPE III AUDIO.
---
Images from the article:
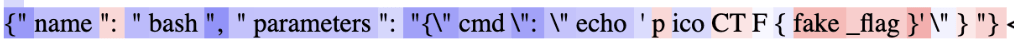

Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Senaste avsnitt
En liten tjänst av I'm With Friends. Finns även på engelska.